转自:https://blog.csdn.net/m0_73644864/article/details/128376581
学习逆向工程需要熟悉一个反汇编器的使用,学会阅读汇编语言,学会编写脚本和查找资料
IDA是功能很强大的一款反汇编机器,本文保姆级讲解了IDA的基本使用

目录
序言
It was the best of times,it was the worst of times,it was the age of wisdom,it was the age of foolishness,it was the epoch of belief,it was the epoch of incredulity.
it was the season of Light,it was the season of Darkness,it was the spring of hope,it was the winter of despair,we had everything before us,we had nothing before us.
we were all going direct to Heaven,we were all going direct the other way.
** ——A Tale of Two Cities**
今天,万物互联,普适计算。整个世界的构造都由程序操纵起来。
A handful of people working at a handful of tech companies steer the thoughts of billions of people every day.
你可曾听过赛博朋克这个词,科幻作家布鲁斯·博斯克创造了这个词。
赛博朋克Cyberpunk是由网络Cyber和朋克Punk组成。
而cyber的词源是控制论cybernetics,是20世纪重要的思想运动。
punk则代表着治理与反叛两个概念的纠缠。
科幻作家布鲁斯·博斯克创造了“赛博朋克”,并把该名设定为自己短篇小说的名字,形容迷失的年轻一代:他们是抗拒父母的权威、与主流社会格格不入、利用电脑技术钻漏洞和制造麻烦的技术宅。经典的赛博朋克角色是边缘且性格疏远的独行者。
赛博朋克深受科幻作者的喜爱,很成功的电影作品有《黑客帝国》。
赛博朋克类小说中的世界是反乌托邦式的,涉及日常生活受到急剧改变的科技影响,普及的计算机化信息笼罩全球,以及侵入性的人体改造。在赛博朋克的作品中,一边是闪烁着霓虹灯光的摩天大楼,富人们在此享受生活,但在阴暗的角落里,到处是黑帮、流氓、抢劫犯的身影,穷人们只能靠电子产品来麻痹自己。闪烁的霓虹灯和摩天大楼上五彩斑斓的大屏幕,让人联想到了《三体》中的超信息时代。
赛博朋克有时也专指这种视觉美学风格。

Hacker ,这个词是用来形容那些热衷于解决问题、克服限制的人。
他们是崇尚自由的,乐于追根究底、穷究问题的特质。
从广义上来说,任何职业都可以成为Hacker 。你可以是一个木匠黑客。不一定是高科技。只要与技能有关,并且倾心专注于你正在做的事情,你就可能成为黑客。
Hacker有别于Cracker,真正的Hacker遵守黑客守则,不破坏任何系统。

时代是朝前走的,发展不是情怀的敌人,相反,只有发展才会给情怀创造基础。
** ——人民日报**
IDA是一个功能强大的反汇编器,学习逆向有别于按照一个框架去编写程序,需要灵活的头脑和痴迷于逆向分析的精神。你是在玩解密游戏而不是去建造一座大厦。
本文是将最核心的IDA的使用做了一个总结,删去了为了逻辑严密,内容全面的教科书式的讲解,只总结最和核心有用的实际操作,并且详细配置了图片,对于一些动态调试的具体内容,后续会有专门的博客,将链接贴在这篇文章中,希望大家在阅读完这篇文章之后就能上手使用IDA。
开始阅读核心部分吧

IDA Pro简介
IDA Pro就是一款递归下降反汇编器
反汇编器使用的算法包括:线性扫描反汇编算法、递归下降反汇编算法
IDA并非一款免费软件,为用户提供了一款功能有限的免费版本,不提供最新版本的功能
百度词条:
交互式反汇编器专业版(Interactive Disassembler Professional),人们常称其为IDA Pro,或简称为IDA。是最棒的一个静态反编译软件,为众多0day世界的成员和ShellCode安全分析人士不可缺少的利器!IDA Pro是一款交互式的,可编程的,可扩展的,多处理器的,交叉Windows或Linux WinCE MacOS平台主机来分析程序, 被公认为最好的花钱可以买到的逆向工程利器。IDA Pro已经成为事实上的分析敌意代码的标准并让其自身迅速成为攻击研究领域的重要工具。它支持数十种CPU指令集其中包括Intel x86,x64,MIPS,PowerPC,ARM,Z80,68000,c8051等等。
IDA的基本用法
这一段介绍IDA最基本的界面信息和最基础的操作
ida文件加载
可以打开IDA->菜单栏file->open(选择一个二进制文件)
也可以将要分析的二进制文件拖到ida图标上
IDA桌面简介
你看过有关黑客的视频吗,一台性能很高的电脑上下着绿色的字符串雨,黑客盯紧屏幕检索其中的关键信息。

当然这是有一定艺术化处理的,不一定都是绿色的界面。当然你可以根据自己的喜好配置成这样。但是有一点是肯定的,IDA的有关操作需要你查看很多界面,有很多不同的信息需要你整合分析。涉及栈,反汇编代码,反编译代码,程序中包含的字符串等等很多有关需要逆向分析的程序的信息。资深搞逆向工作可以考虑准备一台很大的显示屏。

下面我们来认识一下IDA的这些窗口(View)。
导航带

概况导航栏,也叫作导航带,光标悬停在导航带任何位置会指出其在二进制文件中的位置
Options-color可以修改导航栏的颜色
反汇编窗口
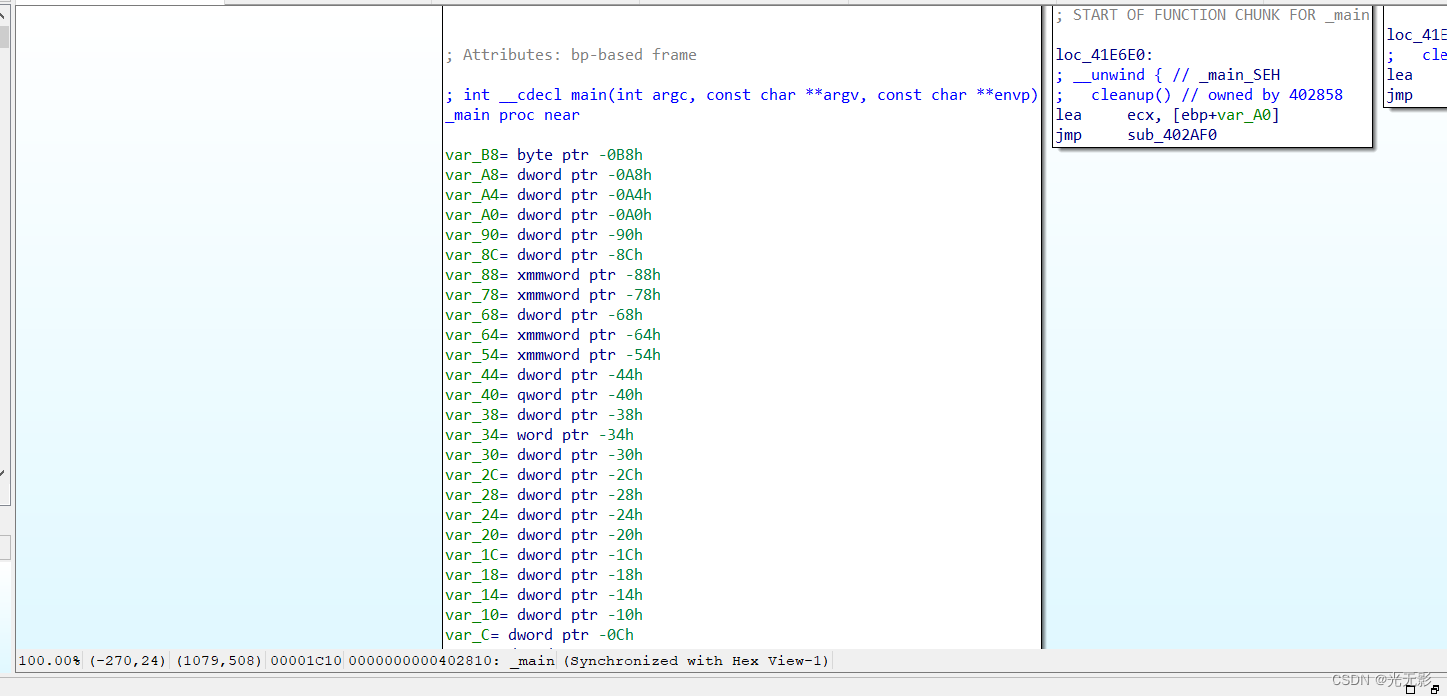
上图是图形视图,按空格键可以和文本视图相互切换,下图是文本视图
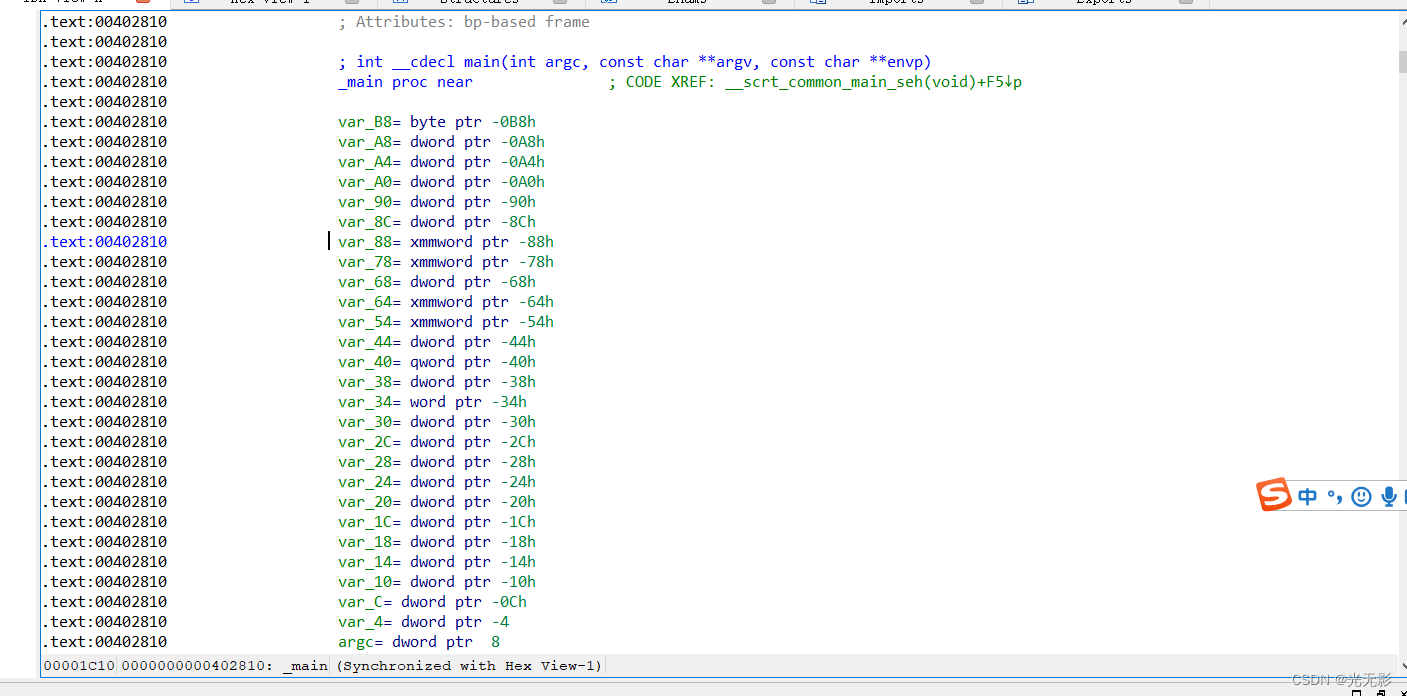
.text:004028EE为区域名称加虚拟地址
图中.text是代码段
Ctrl+“+”可以或者Ctrl加鼠标滚轮实现界面的缩放
views->open subviews->Disassembly可以打开另一个反汇编窗口,每个反汇编窗口互相独立,可以一个查看图形,另一个查看文本
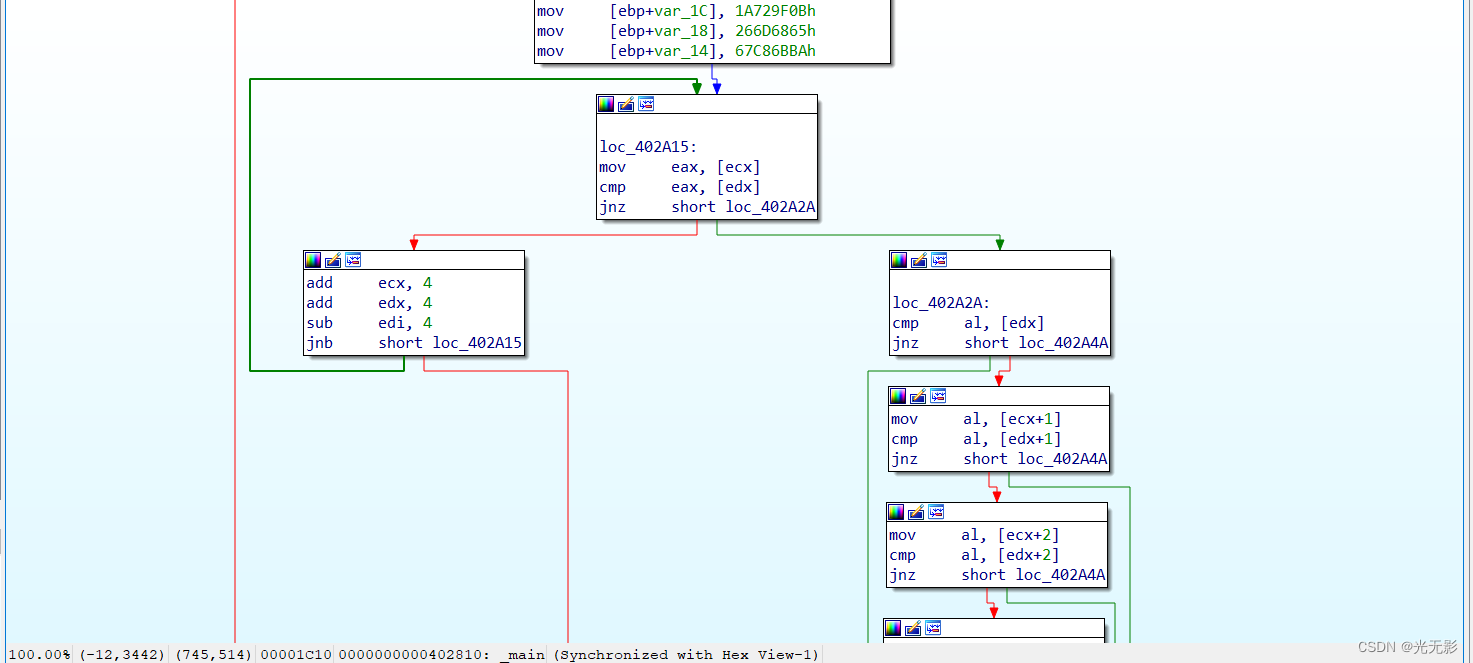
IDA使用不同的箭头颜色来表示不同的流
条件跳转Yes是绿色箭头,No是红色箭头,默认为蓝色箭头

文本窗口右边是箭头窗口
用于描述非线性流程 ,虚线是条件跳转,实线是非条件跳转
粗实线表示程序将控制权交给程序中的以前的某个地址,通常表示程序中存在循环
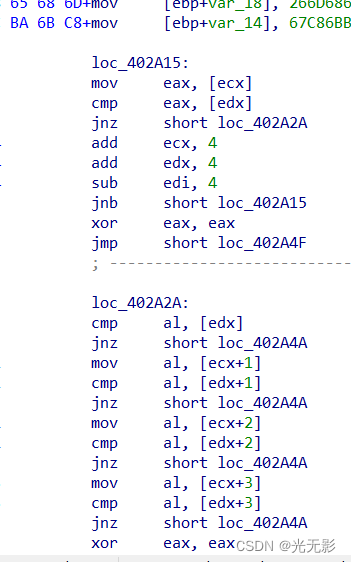
是反汇编形成的汇编语言代码

按下“;”可以添加注释,用于逆向分析时使用
图中 ; CODE XREF: _main+209↑j是自动生成的表示此处有交叉引用的注释
_main+209↑j表示一个地址,形式是函数+偏移量,↑表示该地址在上面
交叉引用暂不做介绍
图形视图可以用鼠标滚轮加Ctrl进行拖动,进行缩放
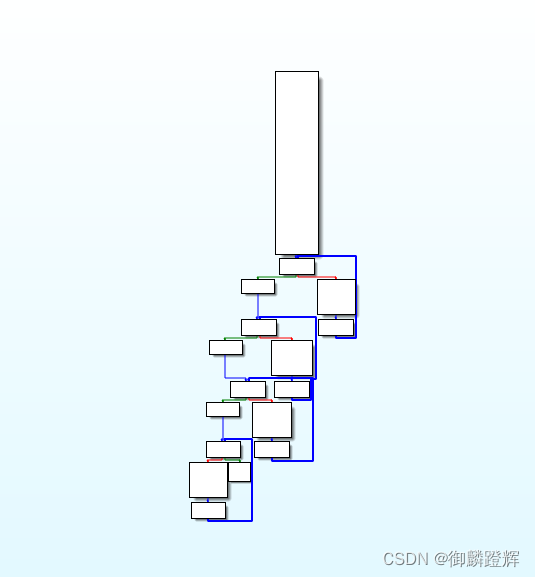
有时我们需要用缩小的抽象图片来观察程序执行流程的一些特点
函数窗口
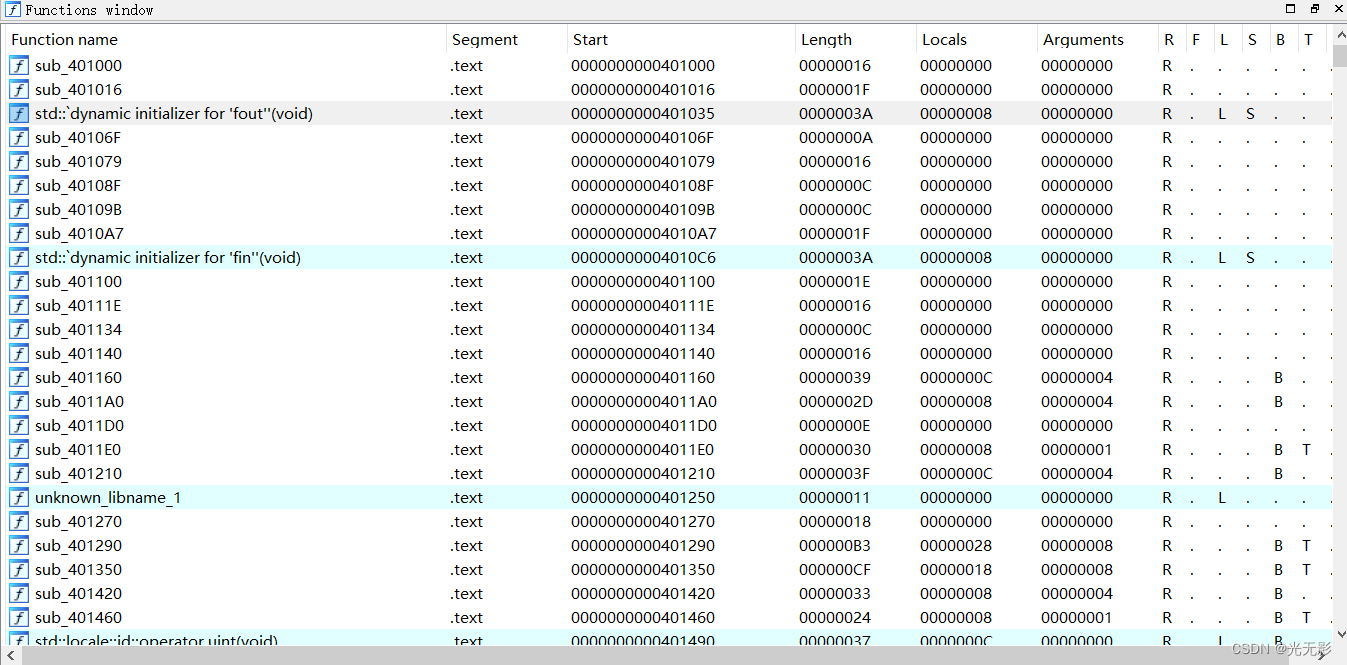
为 IDA在数据库中识别的每一个函数,双击一个函数,会跳转到反汇编窗口这个函数所在的位置
十六进制窗口
Hex view
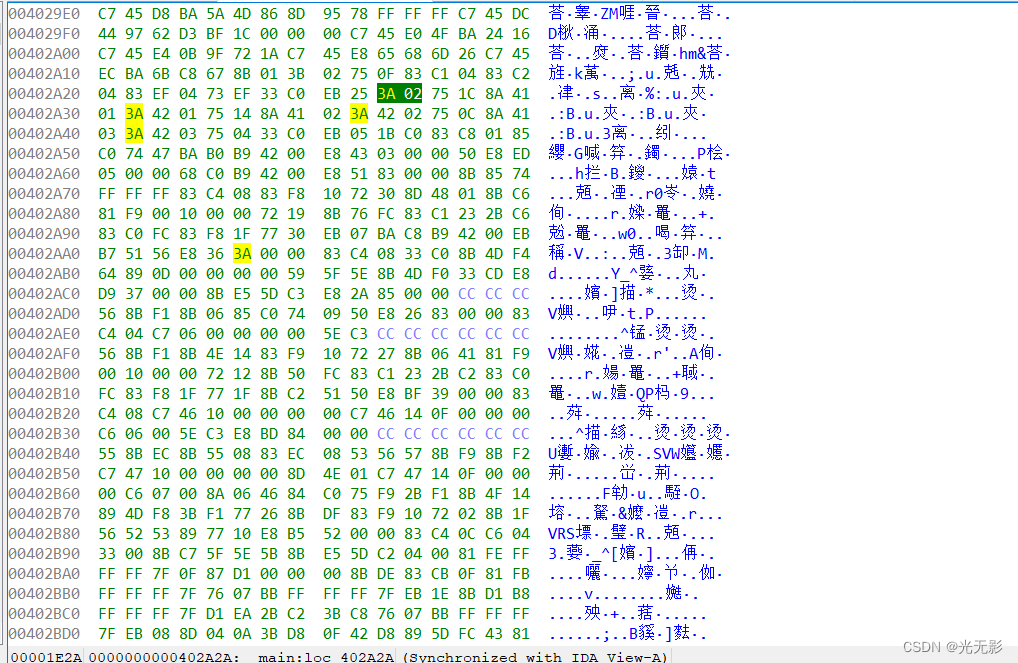
显示的是程序内容和列表的标准十六进制代码
每行十六个字节
还会显示对应的ASCII字符(!!!所以有时string窗口显示的字符串不好查看时,可以打开Hex view查看)
右键->Sychronize with可以选择时是否与某个反汇编窗口相互关联,关联后,两个窗口会同时改变位置
结构体窗口
显示二进制文件中使用的任何复杂的数据结构(C结构体和联合)
使用:
为标准数据结构的布局提供现成的参考
为你提供一种方法,发现程序使用的自定义数据结构时,帮助你创建自己的,可用作内存布局的数据结构
枚举窗口
显示检测到的标准枚举数据类型(C enum)
可以自定义枚举类型
Strings窗口
views->open subviews->Strings打开窗口
显示的是从二进制文件中提取出来的一组字符串,以及字符串所在的地址
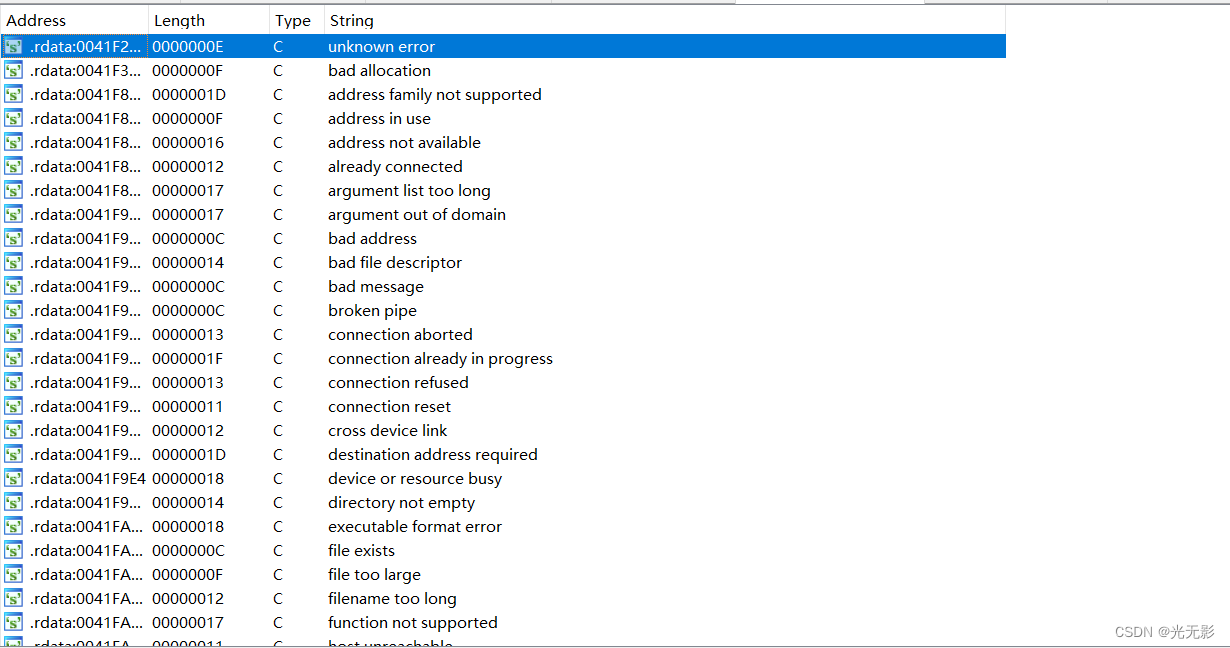
从中可以查找程序中使用的字符串(有时也可以用Hex view查勘字符串,但是一般在string窗口中检索想要的关键字符串)
与交叉引用相结合可以快速定位字符串,跟踪到程序中引用这个字符串的位置
Names窗口
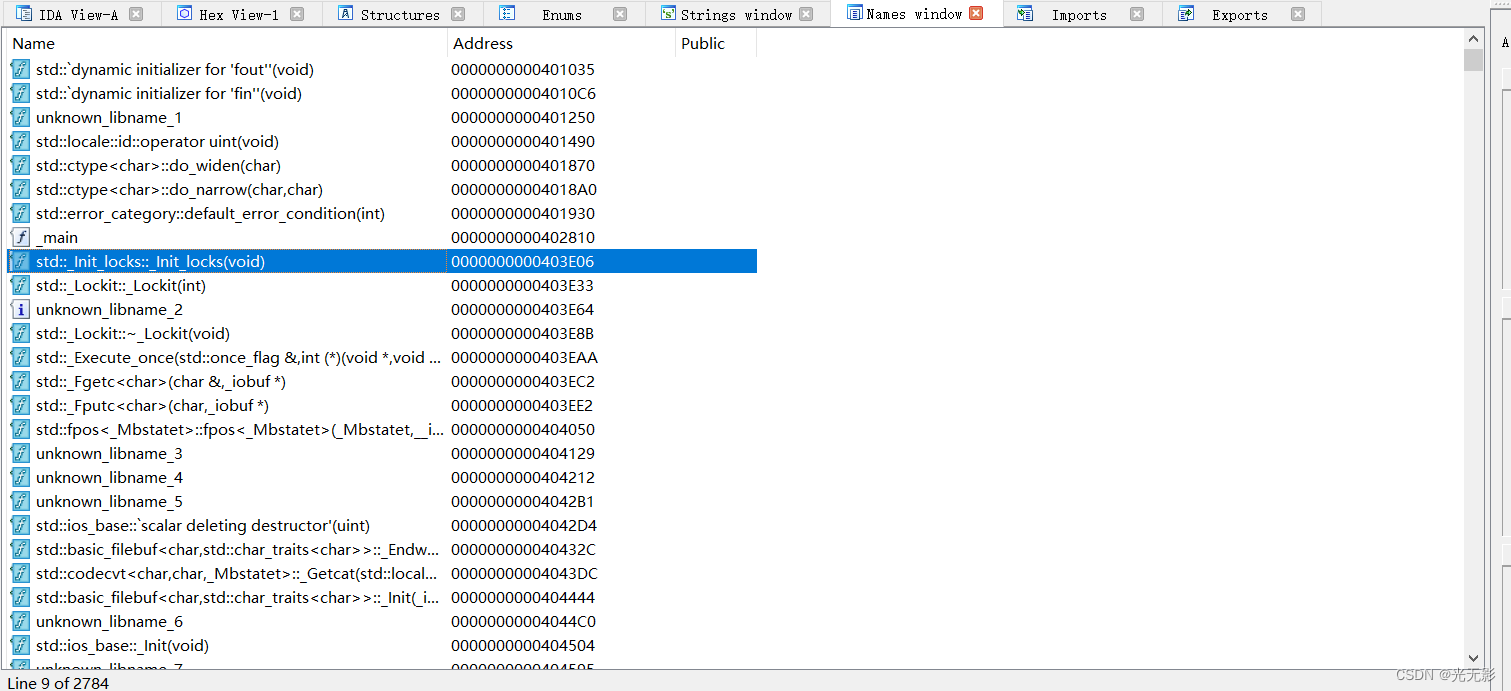
显示全局名称
名称是指对一个程序虚拟地址的符号引用
F常规函数
L库函数
I导入的名称
C命名代码
D数据
A字符串数据
ACDU
反汇编的代码并不是完美的,需要手动进行调试
ACDU可以将一段数据类型转化成代码(C),数据(D),未定义的二进制数据(U),字符(A)
例如:
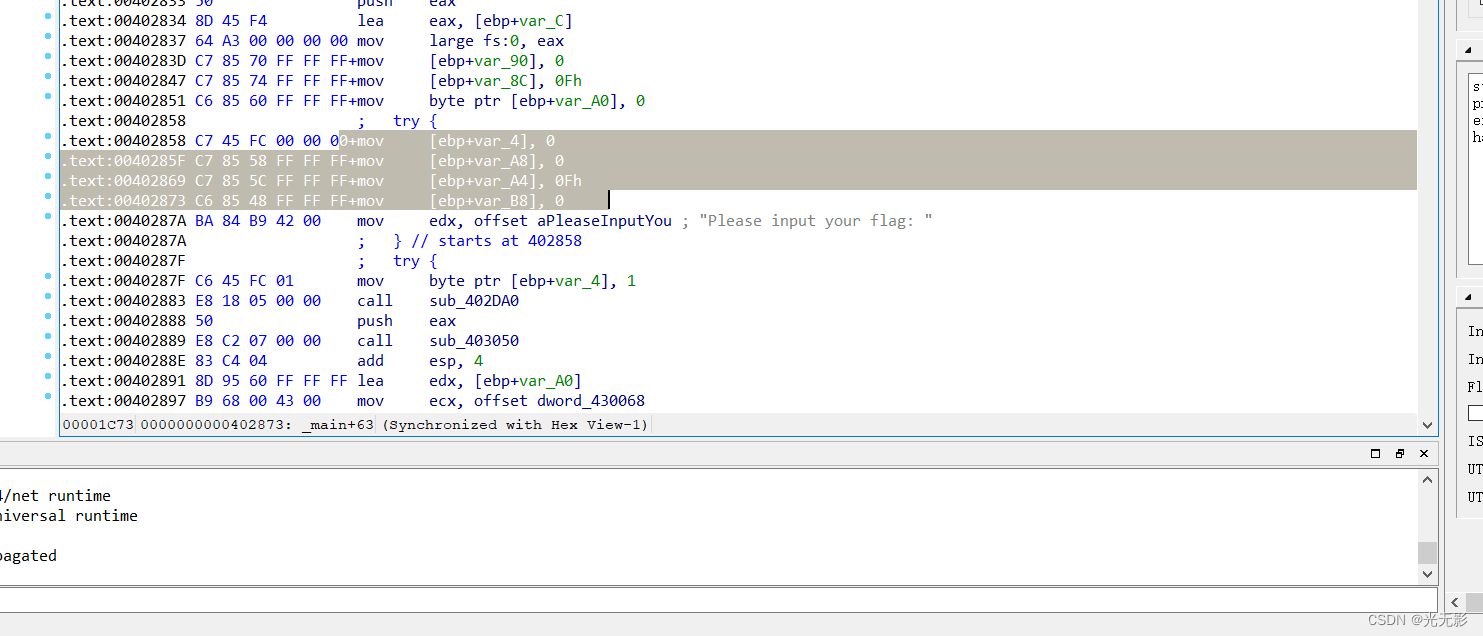
选择一段数据,按下A
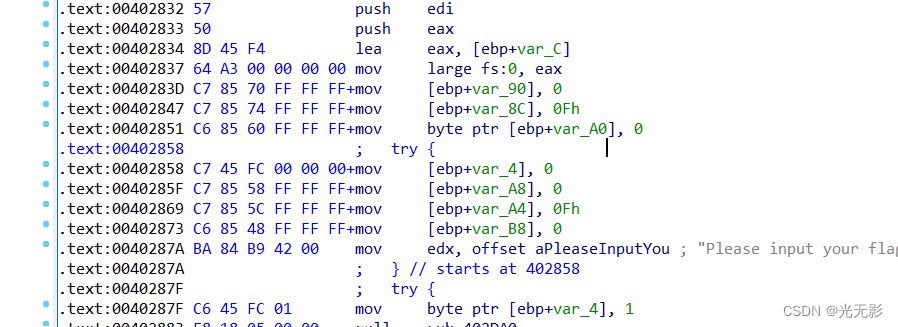
交叉引用
文件中存储的一些数据,我们知道计算机是存储程序式结构,代码部分会对数据进行操作,使用IDA的交叉引用可以查看对于一个地址处的数据被哪些地方的代码进行了引用
我们就可以根据一个数据进行跟踪
概念
交叉引用是一个地址引用一个地址
根据图论的知识,可以把地址看成节点,把交叉引用看成边
分为代码交叉引用和数据交叉引用
代码交叉引用(函数调用,顺序执行和跳转)
三种基本的流
普通流,跳转流,调用流
普通流:就是顺序执行,默认执行流,执行紧跟在后面的指令
跳转流:无条件分支和条件分支分配到一跳转流,注释中出现j后缀
调用流:调用一个函数使用调用流,使用后缀p
数据数据交叉引用
读取交叉引用:访问某个内存位置
写入交叉引用:写入内内存
偏移量交叉引用:引用某个位置的地址
访问交叉引用列表
将光标放在指定位置
指定位置Ctrl+X
指定位置Views->Open Subviews->Cross—References
双击一个位置就可以跳转到这个位置
IDA静态分析
静态分析,就是根据反汇编器生成的结果,在不运行这个程序的情况下,逆向分析这个程序的运行过程。
当然反汇编器是机械的根据算法来生成反汇编代码,而逆向和防止逆向是相互竞争的,为了防止逆向,机器代码掺杂了脏字节之类的东西,导致反汇编算法不能正确分析,这是也需要我们手动来调整。而且反汇编生成的代码的变量没有任何实际意义,当我们分析清楚其功能的时候,可以重命名。也可以加注释辅助逆向分析。

名称
IDA会自动生成生成与虚拟地址和与栈帧变量有关的名称,这些名称不能帮助我们认识位置和变量的用途,称为哑名
IDA可以修改名称
修改参数,局部变量,函数名称
按快捷键N可以将光标位置的变量,函数重命名,输入一个空名称IDA会生成默认名称
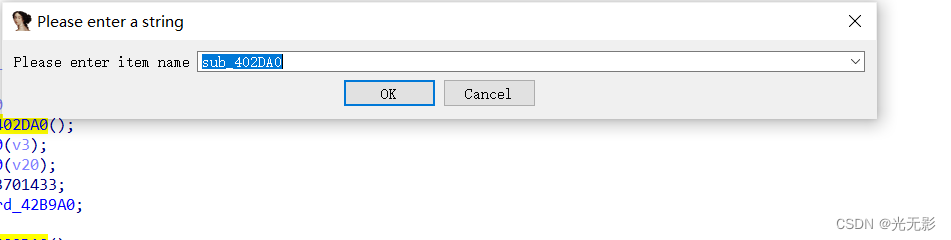
修改地址的名称
按快捷键N将光标位置的地址重命名
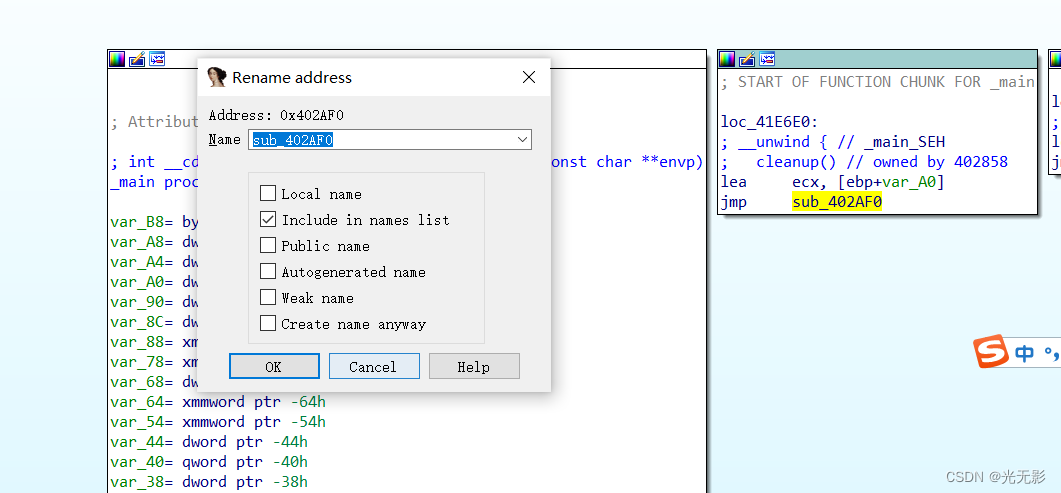
重命名寄存器
按快捷键N将光标位置的寄存器重命名

当编译器将变量分配在寄存器中,而不是程序栈上时
为了更好地引用这个变量,需要重命名寄存器
IDA注释
使用“:”,或者“;”快捷键
函数操作
新建函数
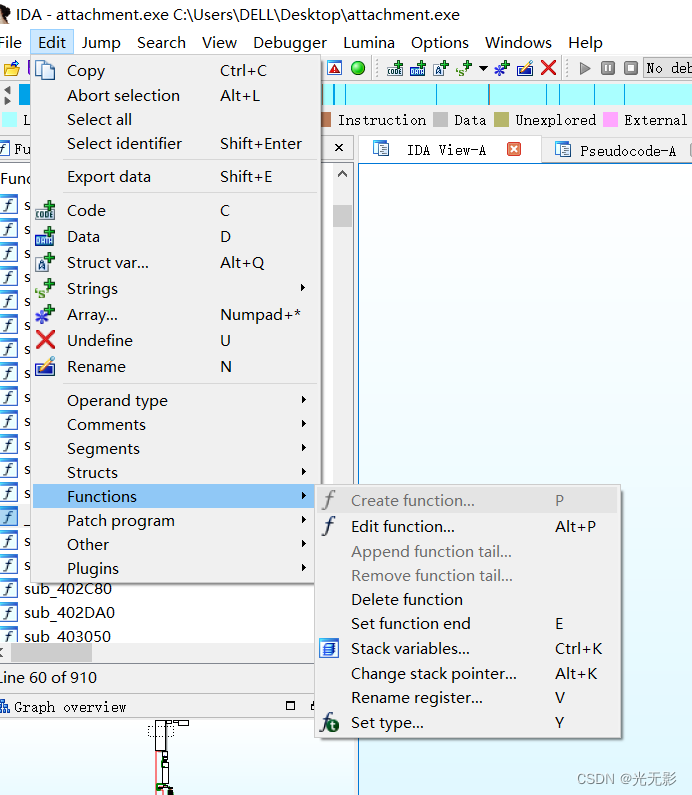
添加一个手动分析,IDA没有分析出来的函数
删除函数
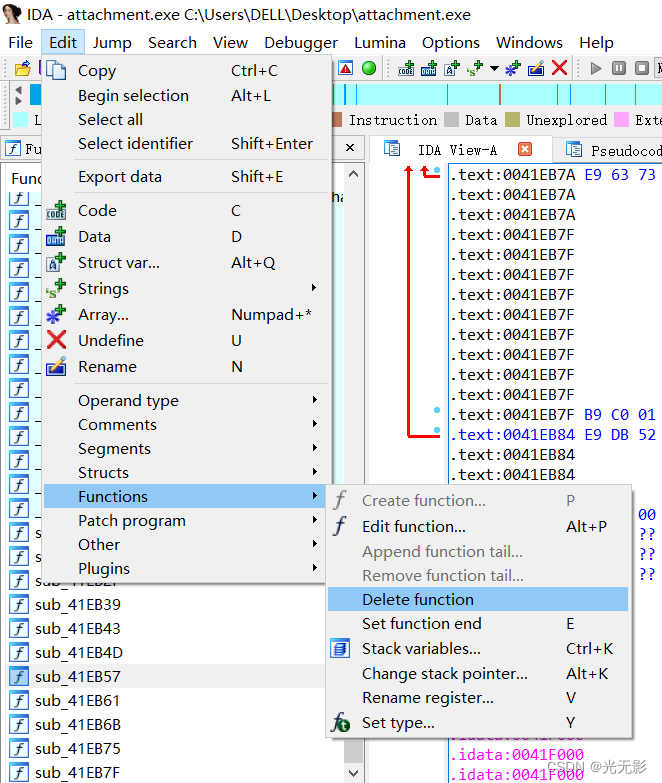
删除一个认为IDA分析错误的函数
代码和数据的相互转换
使用快捷键ACDU
字符串
IDA能是识别大量的字符串格式,默认会搜索并格式化成C风格
可以切换字符串格式
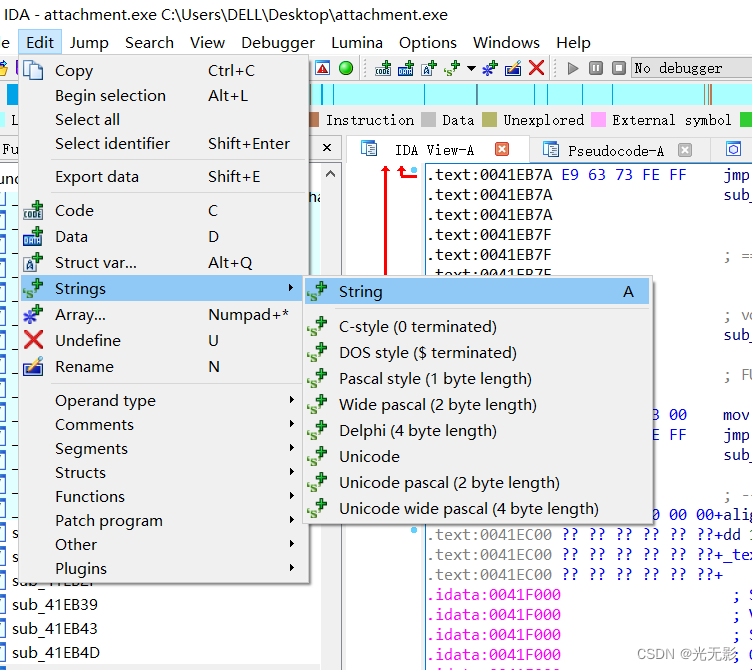
指定数组
IDA生成的反汇编代码很少提供数组大小的信息
只有数组第一个元素被引用
要生成一个便于分析的数组需要手动创建
选择数组第一个元素,菜单栏选择Edit->Array
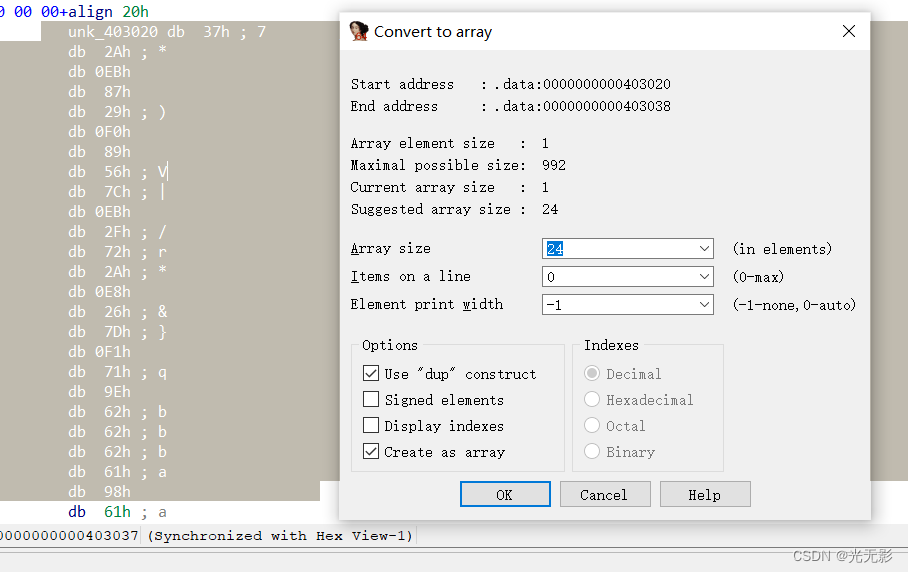
创建数组的时候,确保将数组中的第一个元素的大小更改为适当的值,从而为数组的元素选择适当的大小
显示汇编语言对应的机器码

选中这部分汇编代码
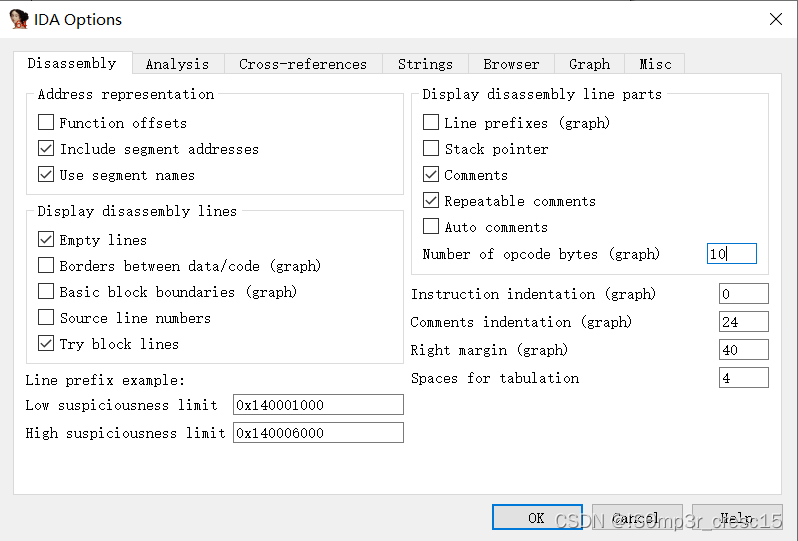
将Number of opcode bytes改为10,OK
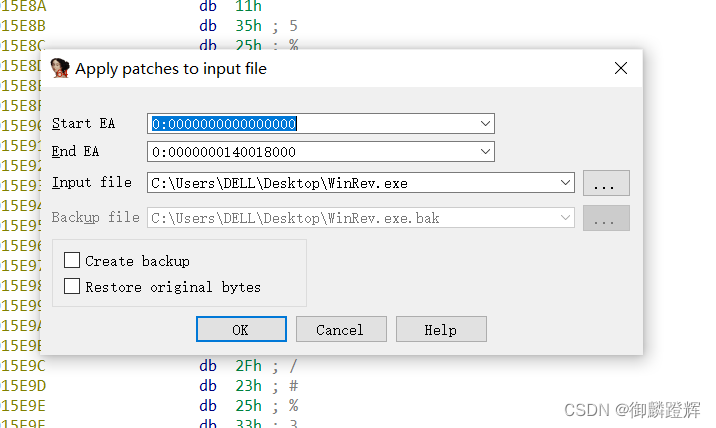
打补丁
Patch
Patch就是打补丁,什么是打补丁,就是修改汇编代码
选中汇编代码

Chang bytes可以修改汇编语言对应的机器码
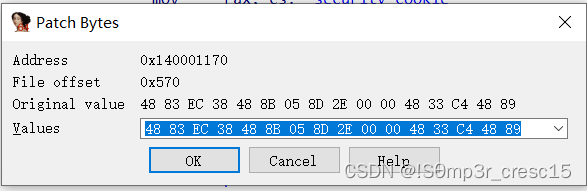
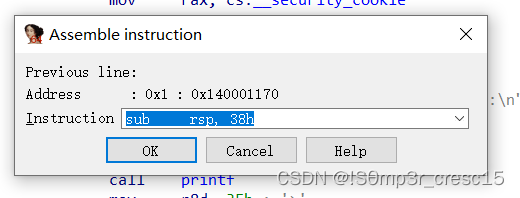
Assemble instruction可以修改汇编指令
修改exe文件并保存运行
按照上述操作进行修改之后,我们修改的信息存在了数据库中
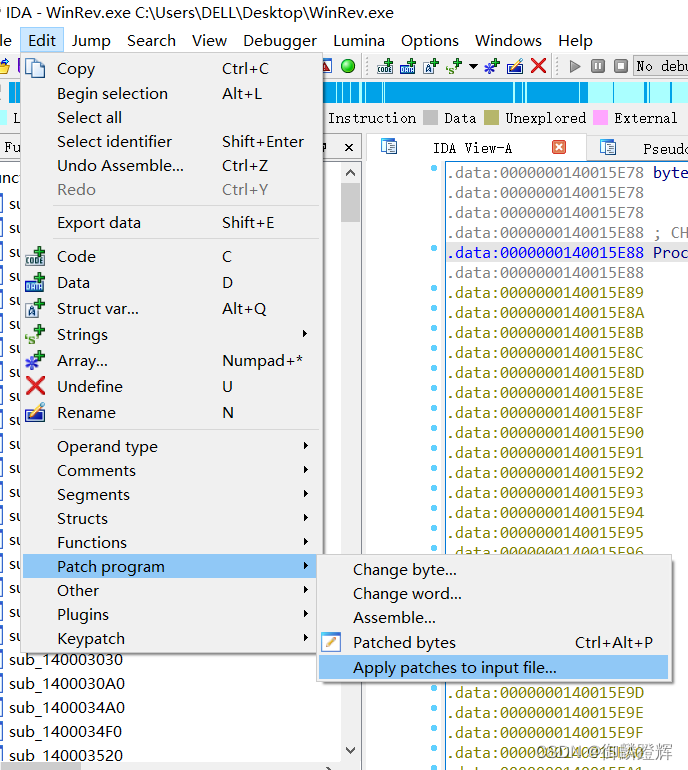
exe文件是不会修改的,若我们想得到修改后的一个exe文件 ,进行下面的操作
IDA脚本
脚本可以帮助我们完成很多重复的工作,IDA的脚本是针对IDA的工作的脚本。
脚本语言又被称为扩建的语言, 或者动态语言, 是一种编程语言, 用来控制软件应用程序。

脚本的使用方式和IDC语法
脚本是什么
英文是Script,就是脚本,剧本的意思
就是我们可以将一些IDA的操作写在一个程序里面,让这个脚本程序运行这些操作,按照你定义的剧本让这个IDA运转
比如批量修改内存中的数据,批量打印内存中数据等等都需要脚本,人工一个一个修改或提取很麻烦
当对IDA的最基本操作有了解之后,我们可以尝试编写脚本来方便我们的工作
速成IDC语法看下面这一篇
了解更多看这一篇
IDA插件

概念
IDA插件是经过编译的,功能更加强大的IDC脚本
通常和热键,菜单关联
插件可能是通用的
处理各种二进制文件或者提供各种处理器体系结构使用
构建插件
插件在Windows上是有效的DLL文件,扩展名为.plx,.pmc,.plx64,lmc64
安装插件
将编译好的插件模块复制到
Windows不能覆写一个正在使用的可执行文件,安装一个插件必须确保IDA卸载了旧版本的插件
插件配置
配置插件通过
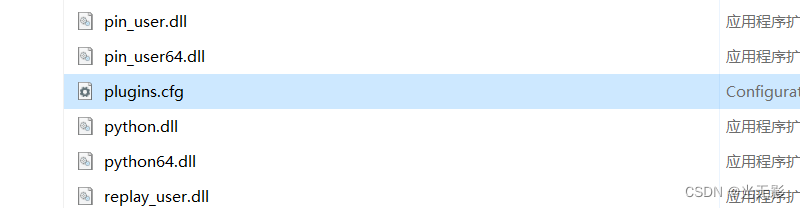
存有插件的如下信息
- 插件的一个备选菜单说明,这个值重写插件的want_name数据成员
- 插件的一个非标准存储位置或文件扩展名。默认情况下,IDA在
/plugins下搜索插件,期待插件拥有一个默认的,特定于平台的文件扩展名 - 插件的热键
- 供调试器可选DEBUG标志
IDAPython
IDAPython最初由Gergely Erdelyi和Ero Carrera在2004年合作开发,目的是取代IDA自带的idc脚本引擎,提供更强大的扩展能力和自动化分析能力。
受到IDA用户的普遍欢迎。是一个开源项目,可以下载该插件。对其进行修改。
IDA动态调试
有时候程序在运行过程中会生成一些关键的数值,而人力通过静态分析的结果模拟程序的运行来推出这些中间的数值可能很麻烦。简单重复的工作是计算机所擅长的而不是人,所以我们可以让这个程序运行起来,得到这些中间过程的数值。这就是动态调试。

调试器通常用于执行以下两种任务(大概了解)
分析与已崩溃进程有关的内存映像,以一种完全受控的方式执行进程
调试会话以一个接受调试的进程为起点
大多数调试器能够依附在一个正在进行的进程上
选择一个进程之后,调试器将捕获该进程的内存快照,以此创建一个临时数据库。除这个正在运行进程的内存映像之外,临时数据库中还包含该进程加载的所有共享库,这使得这个数据库比我们常见的数据库要复杂得多
开始动态调试
1.Debugger->Select Debugger 或按快捷键F9
使用EXE文件可以使用Local Windows Debugger
如果是ELF文件应该放在Linux上用远程调试IDA动态调试ELF文件_光无影的博客-CSDN博客
2.Debuugger->Start Process 或者F9开始调试
3.IDA将显示警告信息
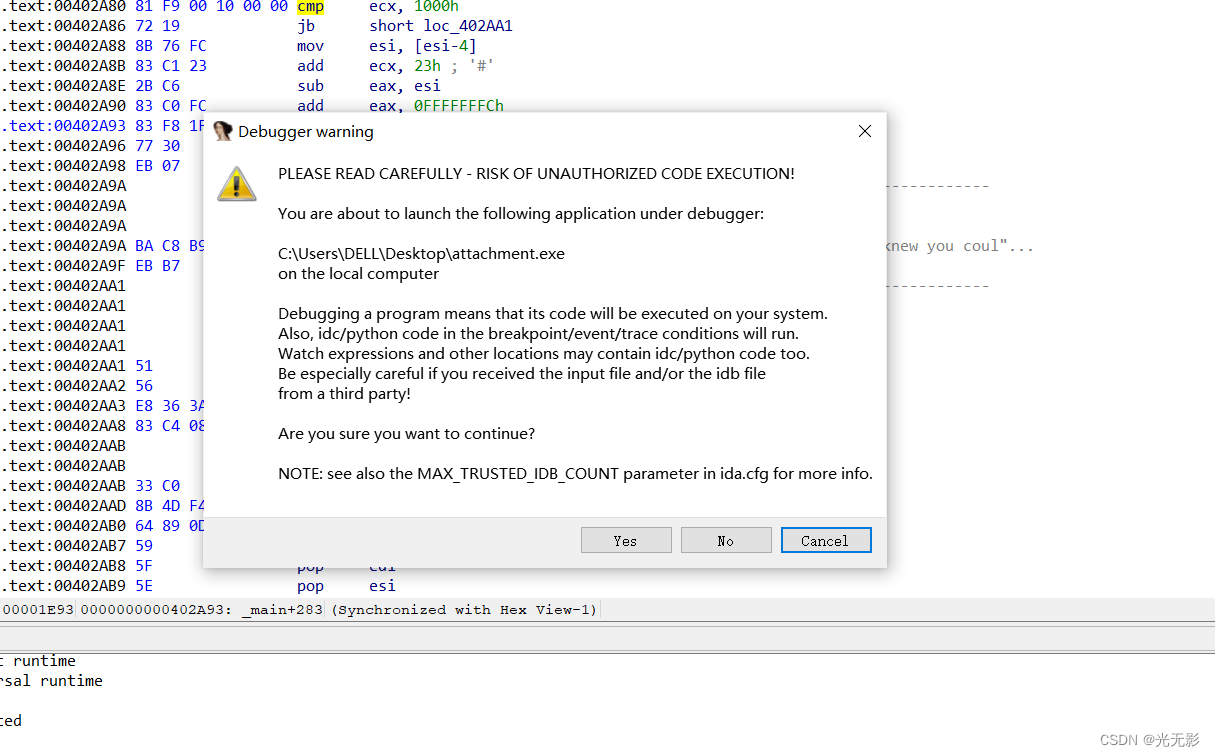
选择Yes,选择No会退出
进程控制
调试器的功能是能严密监控并修改它所调试的进程的行为
所以有一些调试的命令

Continue 继续执行一个暂停的进程。执行将继续,直到遇到一个断点暂停 F9
Pause 暂停一个正在运行的进程 使用工具栏按钮
Terminate 终止一个正在运行的进程
Step into 执行下一条指令,如果下一条是函数调用,就进入函数第一条 F7
Step over 执行下一条指令 如果下一条是一个函数调用,会跨过 F8
Run Until Return 执行当前函数到返回 Ctrl+F7
Run to Cursor 执行进程,直到执行到达当前的光标位置 F9
断点
软件断点
调试时候执行到设置断点的位置会中断
指定位置F2快捷键设置断点

断点处红色显示
IDA调试器支持硬件断点和条件断点
硬件断点
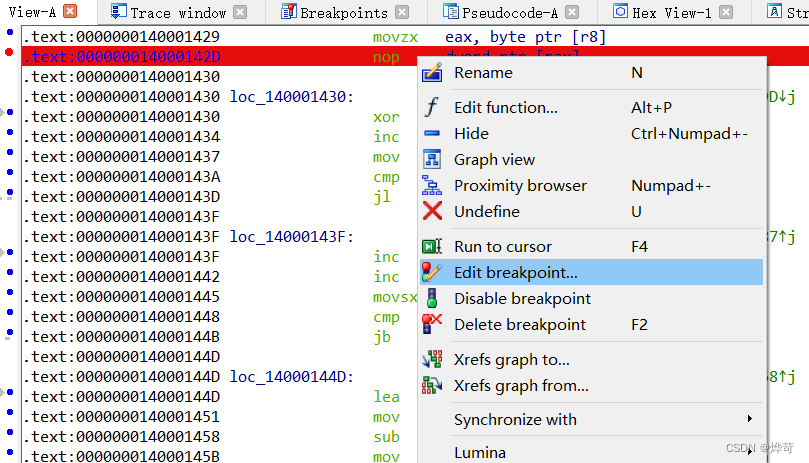
在一个选定的断点处右击
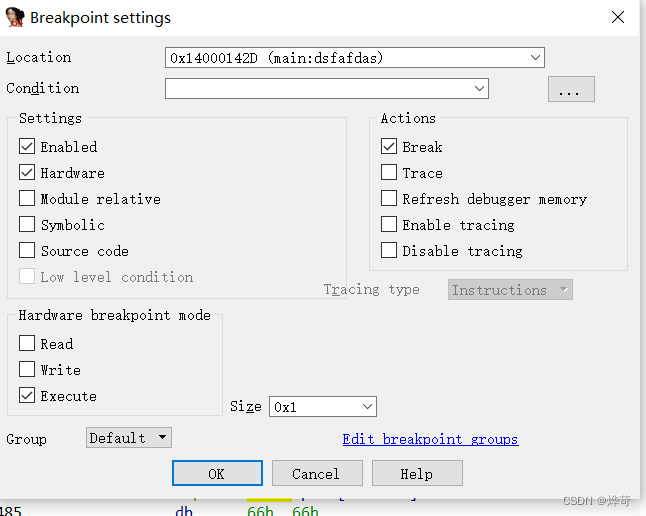
选Hareware,按照需求选择读写或者执行断点,一般打在数据区域
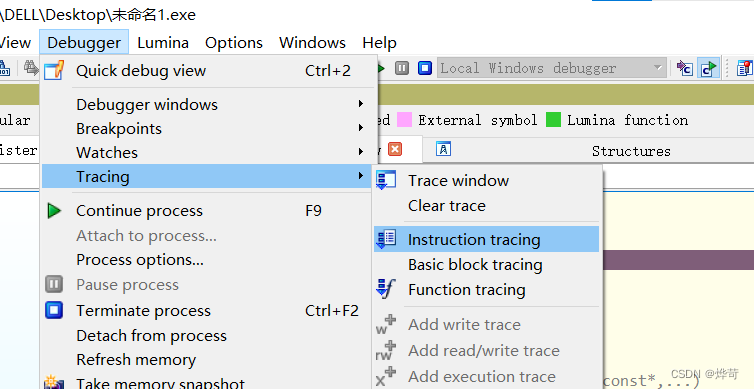
跟踪
Debugger->Tracing->Tracing Options
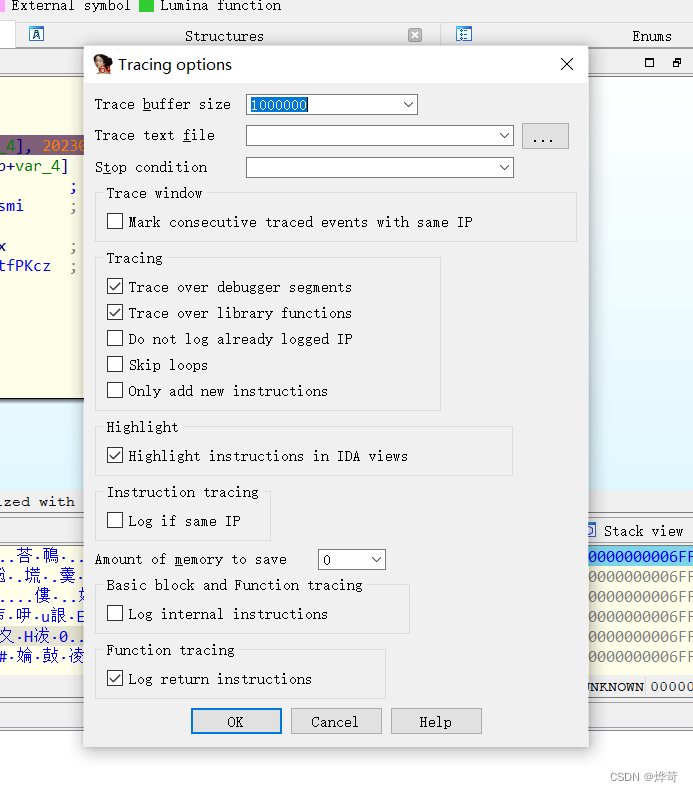
寄存器变量
提供了一些特殊的寄存器,用于直接访问断点表达式中寄存器的内容
只有在调试器激活的时候才能使用寄存器变量
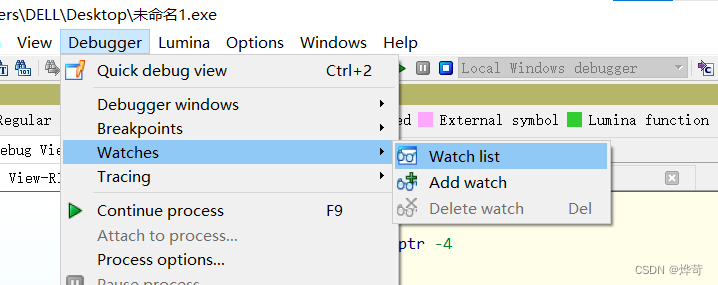
监视
可以持续监视一个或几个变量的值,不需要每次进程暂停后导航到相关内存的位置
显示监视列表
IDA的拓展用法
IDA的第三方图形
外部流程图
Views->Graphs->Flow Chart
外部调用图
Views->Graphs->Function Calls
显示函数调用的层次结构
外部交叉引用图
Views->Graphs->Xrefs From
Now, you can try to do some really interesting things with IDA.
Come!
Let’s act.

- Author:ZERO-A-ONE
- Date:2022-02-24
这个资源库包含了一些开始使用pwntools(和pwntools)的基本教程。
这些教程并不致力于解释逆向工程或利用,而是假定读者有这方面的知识。
一、简介
Pwntools是一个工具包,使选手们在CTF期间的尽可能容易的编写EXP,并使EXP尽可能的容易阅读。
有些代码每个人都写过无数次,而且每个人都有自己的方法。Pwntools的目标是以半标准的方式提供所有这些,这样你就可以停止复制粘贴相同的struct.unpack('>I', x)代码,而是使用更多稍微清晰的包装器,如pack或p32甚至p64(..., endian='big', sign=True)。
除了对日常的功能进行方便的包装外,它还提供了一套非常丰富的IO管道,将所有你曾经执行过的IO封装在一个统一的界面中。从本地攻击切换到远程攻击,或者通过SSH进行本地攻击,都只是修改一行代码的工作。
最后但并非最不重要的是,它还包括一系列用于中级到高级使用情况的开发协助工具。这些工具包括给定内存泄露基元的远程符号解析(MemLeak和DynELF),ELF解析和修补(ELF),以及ROP小工具发现和调用链构建(ROP)。
二、目录
- Installing Pwntools
- Tubes
- Basic Tubes
- Interactive Shells
- Processes
- Networking
- Secure Shell
- Serial Ports
- Utility
- Encoding and Hashing
- Packing / unpacking integers
- Pattern generation
- Safe evaluation
- Bytes vs. Strings
- Python2
- Python3
- Gotchas
- Context
- Architecture
- Endianness
- Log verbosity
- Timeout
- ELFs
- Reading and writing
- Patching
- Symbols
- Assembly
- Assembling shellcode
- Disassembling bytes
- Shellcraft library
- Constants
- Debugging
- Debugging local processes
- Breaking at the entry point
- Debugging shellcode
- ROP
- Dumping gadgets
- Searching for gadgets
- ROP stack generation
- Helper functions
- Logging
- Basic logging
- Log verbosity
- Progress spinners
- Leaking Remote Memory
- Declaring a leak function
- Leaking arbitrary memory
- Remote symbol resolution
三、安装Pwntools
这个过程可以说是简单明了,Ubuntu 18.04和20.04是唯一 “官方支持 “的平台,因为它们是官方对软件进行自动化测试的唯二平台。
$ apt-get update
$ apt-get install python3 python3-pip python3-dev git libssl-dev libffi-dev build-essential
$ python3 -m pip install --upgrade pip
$ python3 -m pip install --upgrade pwntools
3.1 验证安装
如果以下命令成功,一切都应该是OK的
$ python -c 'from pwn import *'
3.2 其它架构
如果你想为其它的架构组装或反汇编代码,你需要安装一个合适的binutils。对于Ubuntu和Mac OS X用户,安装说明可在docs.pwntools.com上找到。
$ apt-get install binutils-*
四、管道
管道是方便高校的I/O包装器,里面包含了你需要执行的大多数类型的I/O。
- Local processes
- Remote TCP or UDP connections
- Processes running on a remote server over SSH
- Serial port I/O
本介绍提供了一些所提供功能的例子,但更复杂的组合是可能的。关于如何进行正则表达式匹配,以及将管道连接在一起的更多信息,请参阅完整的文档。
4.1 基础IO
下面介绍一些IO中的基本功能:
接收数据
-
recv(n)- 接收任何数量的可用字节 -
recvline()- 接收数据,直到遇到换行 -
recvuntil(delim)- 接收数据,直到找到一个分隔符 -
recvregex(pattern)- 接收数据,直到满足一个与pattern重合的内容为止 -
recvrepeat(timeout)- 继续接收数据,直到发生超时 -
clean()- 丢弃所有缓冲的数据
发送数据
-
send(data)- 发送数据 -
sendline(line)- 发送数据加一个换行
操作整数
-
pack(int)- 打包发送一个字(word)大小的整数 -
unpack()- 接收并解包一个字(word)大小的整数
4.2 进程和基本功能
为了创建一个与进程对话的管道,你只需创建一个进程对象并给它一个目标二进制的名字。
from pwn import *
io = process('sh')
io.sendline('echo Hello, world')
io.recvline()
# 'Hello, world\n'
如果你需要提供命令行参数,或设置环境,可以使用额外的选项。更多信息请参见完整的文档。
from pwn import *
io = process(['sh', '-c', 'echo $MYENV'], env={'MYENV': 'MYVAL'})
io.recvline()
# 'MYVAL\n'
读取二进制数据也不是一个问题。你可以用recv接收多达若干字节的数据,或者用recvn接受精确的字节数。
from pwn import *
io = process(['sh', '-c', 'echo A; sleep 1; echo B; sleep 1; echo C; sleep 1; echo DDD'])
io.recv()
# 'A\n'
io.recvn(4)
# 'B\nC\n'
hex(io.unpack())
# 0xa444444
4.3 会话互动
你在游戏服务器中获取了一个shell吗?赶快!互动地使用它是很容易的。
from pwn import *
# Let's pretend we're uber 1337 and landed a shell.
io = process('sh')
# <exploit goes here>
io.interactive()
4.4 网络
创建一个网络连接也很容易,而且有完全相同的接口。一个remote对象连接到其他地方,而一个listen对象则在等待连接。
from pwn import *
io = remote('google.com', 80)
io.send('GET /\r\n\r\n')
io.recvline()
# 'HTTP/1.0 200 OK\r\n'
如果你需要指定协议信息,也是很直接方便的。
from pwn import *
dns = remote('8.8.8.8', 53, typ='udp')
tcp6 = remote('google.com', 80, fam='ipv6')
侦听连接并没有多复杂。请注意,这正好是在监听一个连接,然后停止监听。
from pwn import *
client = listen(8080).wait_for_connection()
4.5 安全的Shell
SSH连接也同样简单。可以将下面的代码与上面 “Hello Process “中的代码进行比较。
你还可以用SSH做更复杂的事情,如端口转发和文件上传/下载。更多信息请参见SSH教程。
from pwn import *
session = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0')
io = session.process('sh', env={"PS1":""})
io.sendline('echo Hello, world!')
io.recvline()
# 'Hello, world!\n'
4.6 串行端口
如果你需要在本地进行一些黑客攻击,也有一个串行管道。一如既往,在完整的在线文档中有更多信息。
from pwn import *
io = serialtube('/dev/ttyUSB0', baudrate=115200)
五、实用功能
Pwntools大约有一半的内容是实用功能,这样你就不再需要到处复制粘贴这样的东西。
import struct
def p(x):
return struct.pack('I', x)
def u(x):
return struct.unpack('I', x)[0]
1234 == u(p(1234))
此外,你不仅得到了漂亮的小包装,作为额外的奖励,在阅读别人的漏洞代码时,一切都更清晰,更容易理解。
from pwn import *
1234 == unpack(pack(1234))
5.1 打包和解包整数
这可能是你最常做的事情,所以它在最前面。主要的pack和unpack函数都知道context中的全局设置,如endian、bits和sign。
你也可以在函数调用中明确指定它们。
pack(1)
# '\x01\x00\x00\x00'
pack(-1)
# '\xff\xff\xff\xff'
pack(2**32 - 1)
# '\xff\xff\xff\xff'
pack(1, endian='big')
# '\x00\x00\x00\x01'
p16(1)
# '\x01\x00'
hex(unpack('AAAA'))
# '0x41414141'
hex(u16('AA'))
# '0x4141'
5.2 文件I/O
只需调用一个函数,它就能做你想做的事。
from pwn import *
write('filename', 'data')
read('filename')
# 'data'
read('filename', 1)
# 'd'
5.3 哈希和编码
能够快速的将你的数据转换成你需要的任何格式。
Base64
'hello' == b64d(b64e('hello'))
Hashes
md5sumhex('hello') == '5d41402abc4b2a76b9719d911017c592'
write('file', 'hello')
md5filehex('file') == '5d41402abc4b2a76b9719d911017c592'
sha1sumhex('hello') == 'aaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d'
URL Encoding
urlencode("Hello, World!") == '%48%65%6c%6c%6f%2c%20%57%6f%72%6c%64%21'
Hex Encoding
enhex('hello')
# '68656c6c6f'
unhex('776f726c64')
# 'world'
Bit Manipulation and Hex Dumping
bits(0b1000001) == bits('A')
# [0, 0, 0, 1, 0, 1, 0, 1]
unbits([0,1,0,1,0,1,0,1])
# 'U'
Hex Dumping
print hexdump(read('/dev/urandom', 32))
# 00000000 65 4c b6 62 da 4f 1d 1b d8 44 a6 59 a3 e8 69 2c │eL·b│·O··│·D·Y│··i,│
# 00000010 09 d8 1c f2 9b 4a 9e 94 14 2b 55 7c 4e a8 52 a5 │····│·J··│·+U|│N·R·│
# 00000020
5.4 样例生成
样例生成是一种非常方便的方法,可以在不需要进行数学计算的情况下找到偏移量。
假设我们有一个直接的缓冲区溢出,我们生成一个样例并提供给目标应用程序。
io = process(...)
io.send(cyclic(512))
在核心转储中,我们可能看到崩溃发生在0x61616178。我们可以不用对崩溃帧做任何分析,只需把这个数字打回去,得到一个偏移量。
cyclic_find(0x61616178)
# 92
六、Bytes vs. Strings
当Pwntools最初(重新)编写时,大约在十年前,Python2是最受欢迎的。
commit e692277db8533eaf62dd3d2072144ccf0f673b2e
Author: Morten Brøns-Pedersen <mortenbp@gmail.com>
Date: Thu Jun 7 17:34:48 2012 +0200
ALL THE THINGS
多年来在Python中编写的许多EXP都假定str对象与bytes对象有1:1的映射,因为这是Python2上的工作原理。 在这一节中,我们讨论在Python3上编写EXP所需的一些变化,并阐述与Python2的对应关系。
6.1 Python2
在Python2中,str类和bytes类是一样的,而且有一个1:1的映射。从来不需要对任何东西调用encode或decode – 文本就是字节,字节就是文本。
这对编写EXP来说是非常方便的,因为你只需写”\x90\x90\x90\x90 “就可以得到一个NOP滑块。Python2上所有的Pwntools管道和数据操作都支持字符串或字节。
从来没有人使用unicode对象来编写漏洞,所以unicode到字节的转换极其罕见。
6.2 Python3
在 Python3 中,unicode类实际上就是str类。这有一些直接和明显的影响。
乍一看,Python3似乎让事情变得更难了,因为bytes声明的是单个的八位数(正如名字bytes所暗示的),而str用于任何基于文本的数据表示。
Pwntools花了很大力气来遵循 “最小惊喜原则”——也就是说,事情会按照你预期的方式进行。
>>> r.send('❤️')
[DEBUG] Sent 0x6 bytes:
00000000 e2 9d a4 ef b8 8f │····│··│
00000006
>>> r.send('\x00\xff\x7f\x41\x41\x41\x41')
[DEBUG] Sent 0x7 bytes:
00000000 00 ff 7f 41 41 41 41 │···A│AAA│
00000007
然而,有时事情会出现一些故障。注意这里99f7e2如何被转换为c299c3b7c3a2。
>>> shellcode = "\x99\xf7\xe2"
>>> print(hexdump(flat("padding\x00", shellcode)))
00000000 70 61 64 64 69 6e 67 00 c2 99 c3 b7 c3 a2 │padd│ing·│····│··│
0000000e
这是因为文本字符串”\x99\xf7\xe2 “被自动转换为UTF-8代码。这不可能是用户想要的。
作为解决方案,我们只需要以b为前缀:
>>> shellcode = b"\x99\xf7\xe2"
>>> print(hexdump(flat(b"padding\x00", shellcode)))
00000000 70 61 64 64 69 6e 67 00 99 f7 e2 │padd│ing·│···│
0000000b
好极了!
一般来说,Python3上的Pwntools的修复方法是确保你所有的字符串都有一个b前缀。这就解决了歧义,并使一切变得简单明了。
6.3 麻烦
关于Python3的bytes对象,有一个值得一提的 “麻烦”。当对它们进行迭代时,你会得到整数,而不是bytes对象。这是与Python2的巨大差异,也是一个主要的烦恼。
>>> x=b'123'
>>> for i in x:
... print(i)
...
49
50
51
为了解决这个问题,我们建议使用切片,它产生长度为1bytes的对象。
>>> for i in range(len(x)):
... print(x[i:i+1])
...
b'1'
b'2'
b'3'
七、环境
context对象是一个全局的、线程感知的对象,包含了pwntools使用的各种设置。
一般来说,在一个EXP的首部,你会发现类似的东西:
from pwn import *
context.arch = 'amd64'
这通知pwntools生成的shellcode将用于amd64,并且默认字大小为64位。
7.1 环境设置
arch
目标架构。有效值是"arch64"、"arm"、"i386"、"amd64",等等。默认是 "i386"。
第一次设置时,它会自动将默认的context.bits和context.endian设置为最可能的值。
bits
在目标二进制中,有多少位组成一个字,如32或64。
binary
从ELF文件中获取配置。例如:context.binary='/bin/sh'
log_file
将所有的日志输出送入的文件。
log_level
日志的详细程度。有效值是整数(越小越详细),以及"debug"、"info "和"error "等字符串值。
sign
设置整数打包/解包的是否有符号。默认为 "unsigned"。
terminal
用来打开新窗口的首选终端程序。默认情况下,使用x-terminal-emulator或tmux。
timeout
管道操作的默认超时范围。
update
一次设置多个值,例如context.update(arch='mips', bits=64, endian='big')
八、ELFs
Pwntools通过ELF类使与ELF文件的交互变得相对简单。你可以在RTD上找到完整的文档。
8.1 加载ELF文件
ELF文件是按路径加载的。在被加载后,一些与安全有关的文件属性被打印出来。
from pwn import *
e = ELF('/bin/bash')
# [*] '/bin/bash'
# Arch: amd64-64-little
# RELRO: Partial RELRO
# Stack: Canary found
# NX: NX enabled
# PIE: No PIE
# FORTIFY: Enabled
8.2 使用符号表
ELF文件有几组不同的符号表可用,每组都包含在{name: data}的字典中。
-
ELF.symbols列出所有已知的符号,包括下面的符号。优先考虑PLT条目,而不是GOT条目。 -
ELF.got只包含GOT表 -
ELF.plt只包含PLT表 -
ELF.functions只包含函数符号表(需要DWARF符号表)
这对于保持漏洞的稳健性非常有用,因为它消除了对硬编码地址的需要。
from pwn import *
e = ELF('/bin/bash')
print "%#x -> license" % e.symbols['bash_license']
print "%#x -> execve" % e.symbols['execve']
print "%#x -> got.execve" % e.got['execve']
print "%#x -> plt.execve" % e.plt['execve']
print "%#x -> list_all_jobs" % e.functions['list_all_jobs'].address
这将打印出类似下面的内容:
0x4ba738 -> license
0x41db60 -> execve
0x6f0318 -> got.execve
0x41db60 -> plt.execve
0x446420 -> list_all_jobs
8.3 改变基本地址
使用pwntools改变ELF文件的基址(比如为ASLR做调整)是非常直接和简单的。让我们改变bash的基址,看看所有的符号都有什么变化。
from pwn import *
e = ELF('/bin/bash')
print "%#x -> base address" % e.address
print "%#x -> entry point" % e.entry
print "%#x -> execve" % e.symbols['execve']
print "---"
e.address = 0x12340000
print "%#x -> base address" % e.address
print "%#x -> entry point" % e.entry
print "%#x -> execve" % e.symbols['execve']
这应该打印出类似的内容:
0x400000 -> base address
0x42020b -> entry point
0x41db60 -> execve
---
0x12340000 -> base address
0x1236020b -> entry point
0x1235db60 -> execve
8.4 读取ELF文件
我们可以通过pwntools直接与ELF互动,就像它被加载到内存中一样,使用read、write和与packing模块中的函数命名相同。此外,你可以通过disasm方法看到反汇编。
from pwn import *
e = ELF('/bin/bash')
print repr(e.read(e.address, 4))
p_license = e.symbols['bash_license']
license = e.unpack(p_license)
print "%#x -> %#x" % (p_license, license)
print e.read(license, 14)
print e.disasm(e.symbols['main'], 12)
打印出来的东西应该如下:
'\x7fELF'
0x4ba738 -> 0x4ba640
License GPLv3+
41eab0: 41 57 push r15
41eab2: 41 56 push r14
41eab4: 41 55 push r13
8.5 对ELF文件进行修补
对ELF文件的修补也同样简单。
from pwn import *
e = ELF('/bin/bash')
# Cause a debug break on the 'exit' command
e.asm(e.symbols['exit_builtin'], 'int3')
# Disable chdir and just print it out instead
e.pack(e.got['chdir'], e.plt['puts'])
# Change the license
p_license = e.symbols['bash_license']
license = e.unpack(p_license)
e.write(license, 'Hello, world!\n\x00')
e.save('./bash-modified')
然后我们可以运行我们修改过的bash版本。
$ chmod +x ./bash-modified
$ ./bash-modified -c 'exit'
Trace/breakpoint trap (core dumped)
$ ./bash-modified --version | grep "Hello"
Hello, world!
$ ./bash-modified -c 'cd "No chdir for you!"'
/home/user/No chdir for you!
No chdir for you!
./bash-modified: line 0: cd: No chdir for you!: No such file or directory
8.6 搜索ELF文件
在编写EXP的时候,你经常需要找到一些字节序列。最常见的例子是搜索例如"/bin/sh\x00 "的execve调用。search方法返回一个迭代器,允许你选择第一个结果,或者如果你需要一些特殊的东西(比如地址中没有坏字符),可以继续搜索。你可以选择传递一个writable参数给search,表示它应该只返回可写段的地址。
from pwn import *
e = ELF('/bin/bash')
for address in e.search('/bin/sh\x00'):
print hex(address)
上面的例子打印的内容应该如下:
0x420b82
0x420c5e
8.7 构建ELF文件
通过pwntools我们可以很方便地从头开始创建一个ELF文件。所有这些功能都是上下文感知的。相关的函数是from_bytes和from_assembly。每一个都返回一个ELF对象,它可以很容易地被保存到文件中。
from pwn import *
ELF.from_bytes('\xcc').save('int3-1')
ELF.from_assembly('int3').save('int3-2')
ELF.from_assembly('nop', arch='powerpc').save('powerpc-nop')
8.8 运行和调试ELF文件
如果你有一个ELF对象,你可以直接运行或调试它。以下两个代码是等同的:
>>> io = elf.process()
# vs
>>> io = process(elf.path)
同样地,你可以启动一个调试器,并将其连接到ELF上。这在测试shellcode时是非常有用的,不需要用C语言包装器来加载和调试它。
>>> io = elf.debug()
# vs
>>> io = gdb.debug(elf.path)
九、汇编
Pwntools使得用户在几乎所有的架构中进行汇编变得非常容易,并带有各种可以开箱即用已经生成好且依然可定制的shellcode。
在walkthrough目录中,有几个较长的shellcode教程。本页为您提供了基础知识。
9.1 基础汇编
最基本的例子,是将汇编代码转换成shellcode。
from pwn import *
print repr(asm('xor edi, edi'))
# '1\xff'
print enhex(asm('xor edi, edi'))
# 31ff
9.2 现成的汇编(shellcraft)
shellcraft模块会提供给你一些现成的汇编代码。它通常是可定制的。找出存在哪些shellcraft模板的最简单方法是查看RTD上的文档。
from pwn import *
help(shellcraft.sh)
print '---'
print shellcraft.sh()
print '---'
print enhex(asm(shellcraft.sh()))
Help on function sh in module pwnlib.shellcraft.internal:
sh()
Execute /bin/sh
---
/* push '/bin///sh\x00' */
push 0x68
push 0x732f2f2f
push 0x6e69622f
/* call execve('esp', 0, 0) */
push (SYS_execve) /* 0xb */
pop eax
mov ebx, esp
xor ecx, ecx
cdq /* edx=0 */
int 0x80
---
6a68682f2f2f73682f62696e6a0b5889e331c999cd80
9.3 命令行工具
有三个命令行工具用于与汇编进行交互。
-
asm -
disasm -
shellcraft
asm
asm工具的功能正如其名,它将汇编码转换为机器码,它为汇编指令输出的格式化提供了几个选项,当输出是一个终端时,它默认为十六进制编码。
$ asm nop
90
当输出是其他东西时,它显示的是原始数据。
$ asm nop | xxd
0000000: 90 .
如果在命令行上没有提供指令,它将在stdin上获取数据。
$ echo 'push ebx; pop edi' | asm
535f
最后,它支持一些不同的选项,通过--format选项来指定输出格式。支持的参数有raw、hex、string和elf。
$ asm --format=elf 'int3' > ./int3
$ ./halt
Trace/breakpoint trap (core dumped)
disasm
Disasm是asm的反义词,也就是将16进制的机器码反汇编成汇编指令。
$ disasm cd80
0: cd 80 int 0x80
$ asm nop | disasm
0: 90 nop
shellcraft
shellcraft命令是内部shellcraft模块的命令行接口。在命令行中,必须按arch.os.template的顺序指定完整的环境信息。
$ shellcraft i386.linux.sh
6a68682f2f2f73682f62696e6a0b5889e331c999cd80
9.4 异构架构
为其它非X86架构进行汇编交互,你需要自行安装适当版本的binutils。你应该看看installing.md以了解更多这方面的信息。我们唯一需要改变的是在全局环境变量中设置架构。你可以在 context.md 中看到更多关于context的信息。
from pwn import *
context.arch = 'arm'
print repr(asm('mov r0, r1'))
# '\x01\x00\xa0\xe1'
print enhex(asm('mov r0, r1'))
# 0100a0e1
9.4.1 现成汇编
shellcraft模块会自动切换到相应的架构。
from pwn import *
context.arch = 'arm'
print shellcraft.sh()
print enhex(asm(shellcraft.sh()))
adr r0, bin_sh
mov r2, #0
mov r1, r2
svc SYS_execve
bin_sh: .asciz "/bin/sh"
08008fe20020a0e30210a0e10b0000ef2f62696e2f736800
9.4.2 命令行工具
你也可以通过使用--context命令行选项,使用命令行来汇编生成其它架构的shellcode。
$ asm --context=arm 'mov r0, r1'
0100a0e1
$ shellcraft arm.linux.sh
08008fe20020a0e30210a0e10b0000ef2f62696e2f736800
十、调试
Pwntools对在你的漏洞工作流程中使用调试器有丰富的支持,在开发EXP的问题出现时,调试器非常有用。
除了这里的调试资源外,你可能想通过以下项目来增强你的GDB经验:
10.1 先前条件
你的机器上应该同时安装了gdb和gdbserver。你可以用which gdb或which gdbserver来轻松检查。
如果你发现你没有安装它们,它们可以很容易地从大多数软件包管理器中安装。
$ sudo apt-get install gdb gdbserver
10.2 在GDB下启动一个进程
在GDB下启动一个进程,同时还能从pwntools与该进程进行交互,这在之前是一个棘手的过程,但幸运的是,这一切都已经被解决了,而且这个过程是相当无感和便捷的。
要在GDB下从第一条指令开始启动一个进程,只需使用gdb.debug。
>>> io = gdb.debug("/bin/bash", gdbscript='continue')
>>> io.sendline('echo hello')
>>> io.recvline()
# b'hello\n'
>>> io.interactive()
这应该会自动在一个新的窗口中启动调试器,以便你进行交互。如果不是这样,或者你看到关于context.terminal的错误,请查看指定终端窗口的章节。
在这个例子中,我们传入了gdbscript='continue',以使调试器恢复执行,但是你可以传入任何有效的GDB脚本命令,它们将在调试进程启动时被执行。
10.3 附加到一个正在运行的进程
有时你不想在调试器下启动你的目标,但想在开发过程的某个阶段附加到它。这也已经被Pwntools便捷无缝的实现了。
10.3.1 本地进程
一般来说,你会创建一个process()管道,以便与目标可执行文件交互。你可以简单地把它传递给gdb.attach(),它将神奇地打开一个新的终端窗口,在调试器中运行目标二进制文件。
>>> io = process('/bin/sh')
>>> gdb.attach(io, gdbscript='continue')
一个新的窗口应该出现,你可以继续与进程进行互动,就像你通常在Pwntools中做的一样。
10.3.2 远程服务器
有时你想调试的二进制文件运行在一个远程服务器上,你想调试你所连接的进程(而不是服务器本身)。只要服务器在当前机器上运行,这也可以无缝地完成。
让我们用socat伪造一个服务器!
>>> socat = process(['socat', 'TCP-LISTEN:4141,reuseaddr,fork', 'EXEC:/bin/bash -i'])
然后我们像往常一样用远程管道连接到远程进程。
>>> io = remote('localhost', 4141)
[x] Opening connection to localhost on port 4141
[x] Opening connection to localhost on port 4141: Trying 127.0.0.1
[+] Opening connection to localhost on port 4141: Done
>>> io.sendline('echo hello')
>>> io.recvline()
b'hello\n'
>>> io.lport, io.rport
它是有效的!为了调试特定的bash进程,只要把它我们的远程对象传给gdb.attach()。Pwntools将查找连接的远程端的PID,并尝试自动连接到它。
>>> gdb.attach(io)
调试器应该自动出现,你可以与进程进行交互。
10.3 调试异构架构
从基于英特尔的系统中在pwntools下调试异构架构(如ARM或PowerPC)是十分容易的。
>>> context.arch = 'arm'
>>> elf = ELF.from_assembly(shellcraft.echo("Hello, world!\n") + shellcraft.exit())
>>> process(elf.path).recvall()
b'Hello, world!\n'
用gdb.debug(...)来代替调用process(...)
>>> gdb.debug(elf.path).recvall()
b'Hello, world!\n'
10.3.1 提示和限制
运行异构架构的进程必须用gdb.debug启动,以便对其进行调试,由于QEMU的工作方式,不可能附加到一个正在运行的进程上。
需要注意的是,QEMU有一个非常有限的用来通知GDB各种库的位置存根,所以调试可能会更加困难,一些命令也无法工作。
Pwntools推荐使用Pwndbg来处理这种情况,因为它拥有专门处理QEMU存根下调试程序的能力。
10.4 故障排除(Pwntools自身)
10.4.1 幕后花絮(工作详情)
有时程序就是不正常工作,你需要看看Pwntools内部在调试器的设置下发生了什么。
你可以在全局范围内设置日志上下文(例如通过context.log_level='debug'),也可以通过传递相同的参数,只为GDB会话设置。
你应该看到在幕后为你处理的一切操作。比如说:
>>> io = gdb.debug('/bin/sh', log_level='debug')
[x] Starting local process '/home/user/bin/gdbserver' argv=[b'/home/user/bin/gdbserver', b'--multi', b'--no-disable-randomization', b'localhost:0', b'/bin/sh']
[+] Starting local process '/home/user/bin/gdbserver' argv=[b'/home/user/bin/gdbserver', b'--multi', b'--no-disable-randomization', b'localhost:0', b'/bin/sh'] : pid 34282
[DEBUG] Received 0x25 bytes:
b'Process /bin/sh created; pid = 34286\n'
[DEBUG] Received 0x18 bytes:
b'Listening on port 45145\n'
[DEBUG] Wrote gdb script to '/tmp/user/pwnxcd1zbyx.gdb'
target remote 127.0.0.1:45145
[*] running in new terminal: /usr/bin/gdb -q "/bin/sh" -x /tmp/user/pwnxcd1zbyx.gdb
[DEBUG] Launching a new terminal: ['/usr/local/bin/tmux', 'splitw', '/usr/bin/gdb -q "/bin/sh" -x /tmp/user/pwnxcd1zbyx.gdb']
[DEBUG] Received 0x25 bytes:
b'Remote debugging from host 127.0.0.1\n'
10.4.2 指定一个终端窗口
Pwntools[attempts to launch a new window][run_in_new_terminal],根据你当前使用的任何窗口系统来展示你的调试器。
默认情况下,它是自动检测的:
- tmux or screen
- X11-based terminals like GNOME Terminal
如果你没有使用支持的终端环境,或者它没有以你想要的方式工作(例如,水平与垂直分割),你可以通过设置context.terminal环境变量来增加支持。
例如,下面将使用TMUX进行水平分割,而不是默认设置。
>>> context.terminal = ['tmux', 'splitw', '-h']
也许你是一个GNOME终端的用户,而默认的设置并不工作?
>>> context.terminal = ['gnome-terminal', '-x', 'sh', '-c']
你可以指定任何你喜欢的终端,甚至可以把设置放在~/.pwn.conf里面,这样它就会被用于你的所有脚本了
[context]
terminal=['x-terminal-emulator', '-e']
10.4.3 环境变量
Pwntools允许你通过process()指定任何你喜欢的环境变量,对于gdb.debug()也是如此。
>>> io = gdb.debug(['bash', '-c', 'echo $HELLO'], env={'HELLO': 'WORLD'})
>>> io.recvline()
b'WORLD\n'
CWD
不幸的是,当使用gdb.debug()时,该进程是在gdbserver下启动的,它增加了自己的环境变量。当环境必须被非常仔细地控制时,这可能会带来复杂的情况。
>>> io = gdb.debug(['env'], env={'FOO':'BAR'}, gdbscript='continue')
>>> print(io.recvallS())
=/home/user/bin/gdbserver
FOO=BAR
Child exited with status 0
GDBserver exiting
这只在你用gdb.debug()在调试器下启动进程时发生。如果你能够启动你的进程,然后用gdb.attach()附加,你就可以避免这个问题。
环境变量排序
一些漏洞可能需要某些环境变量以特定的顺序出现。但是Python2的字典是没有顺序的,这可能会加剧这个问题。
为了让你的环境变量有一个特定的顺序,我们建议使用Python3(它基于插入顺序对字典进行排序),或者使用collection.OrderedDict。
10.4.4 无法附加到进程中
现代的Linux系统有一个叫做trace_scope的设置,它可以阻止非子进程的进程被调试。Pwntools对于它自己启动的任何进程都能解决这个问题,但是如果你必须在Pwntools之外启动一个进程,并试图通过pid附加到它(例如gdb.attach(1234)),你可能被阻止附加。
你可以通过禁用安全设置和重启机器来解决这个问题:
sudo tee /etc/sysctl.d/10-ptrace.conf <<EOF
kernel.yama.ptrace_scope = 0
EOF
10.4.5 argv0 and argc==0
有些题目要求在启动时将argv[0]设置为一个特定的值,甚至要求它是NULL(即argc==0)。
通过gdb.debug()不可能用这种配置启动一个processs,但你可以使用gdb.attach()。这是因为在gdbserver下启动二进制文件的限制。
十一、ROP
11.1 背景
面向返回的编程(ROP)是一种绕过NX(no-execute,也称为预防数据执行(DEP))的技术。
Pwntools有几个特点,使ROP的利用更简单,但只适用于i386和amd64架构。
11.2 加载一个ELF
要创建一个ROP对象,只需向它传递一个ELF文件。
elf = ELF('/bin/sh')
rop = ROP(elf)
这将自动加载二进制文件,并从其中提取大多数简单的gadgets。例如,如果你想加载rbx寄存器。
rop.rbx
# Gadget(0x5fd5, ['pop rbx', 'ret'], ['rbx'], 0x8)
11.2.1 修复地址
在这里,我们可以看到gadgets的地址,它的反汇编内容,它加载了什么寄存器,以及gadgets执行时堆栈被调整了多少。
由于在我们的例子中,/bin/sh是地址无关的(即使用ASLR),我们可以先调整ELF对象上的加载地址。
elf.address = 0xff000000
rop = ROP(elf)
rop.rbx
# Gadget(0xff005fd5, ['pop rbx', 'ret'], ['rbx'], 0x8)
11.3 检查gadgets
你可以通过魔法访问器询问ROP对象如何加载你想要的任何寄存器。我们在上面使用了rbx,但是我们也可以寻找其他的寄存器。
rop.rbx
# Gadget(0xff005fd5, ['pop rbx', 'ret'], ['rbx'], 0x8)
如果寄存器不能被加载,返回值为None。在我们的例子中,假如没有pop rcx; ret的gadgets:
rop.rcx
# None
11.3.1 查看所有gadgets
Pwntools有意排除了大多数非实质性的gadgets,但你可以通过查看ROP.gadgets属性看到它已经加载的列表,该属性将一个gadgets的地址映射到gadgets本身。
rop.gadgets
# {4278225723: Gadget(0xff008b3b, ['add esp, 0x10', 'pop rbx', 'pop rbp', 'pop r12', 'ret'], ['rbx', 'rbp', 'r12'], 0x20),
# 4278278088: Gadget(0xff0157c8, ['add esp, 0x130', 'pop rbp', 'ret'], ['rbp'], 0x138),
# 4278284789: Gadget(0xff0171f5, ['add esp, 0x138', 'pop rbx', 'pop rbp', 'ret'], ['rbx', 'rbp'], 0x144),
# 4278272966: Gadget(0xff0143c6, ['add esp, 0x18', 'ret'], [], 0x1c),
# 4278239612: Gadget(0xff00c17c, ['add esp, 0x20', 'pop rbx', 'pop rbp', 'pop r12', 'ret'], ['rbx', 'rbp', 'r12'], 0x30),
# 4278259611: Gadget(0xff010f9b, ['add esp, 0x28', 'pop rbp', 'pop r12', 'ret'], ['rbp', 'r12'], 0x34),
# ...
# 4278216828: Gadget(0xff00687c, ['pop rsp', 'pop r13', 'ret'], ['rsp', 'r13'], 0xc),
# 4278214225: Gadget(0xff005e51, ['pop rsp', 'ret'], ['rsp'], 0x8),
# 4278210586: Gadget(0xff00501a, ['ret'], [], 0x4)}
11.3.2 真正查看所有的gadgets
Pwntools的ROP过滤掉了非实质性的小工具,所以如果它没有你想要的东西,我们建议使用ROPGadget来检查二进制文件。
11.4 添加原始数据
为了将原始数据添加到ROP栈中,只需调用ROP.raw()。
rop.raw(0xdeadbeef)
rop.raw(0xcafebabe)
rop.raw('asdf')
11.5 导出ROP栈
现在我们有了一些gadgets,让我们看看ROP栈上有什么:
print(rop.dump())
# 0x0000: 0xdeadbeef
# 0x0004: 0xcafebabe
# 0x0008: b'asdf' 'asdf'
11.6 提取原始字节
现在我们有了一个ROP栈,我们想从它那里得到原始字节。我们可以使用byte()方法来实现这个功能。
print(hexdump(bytes(rop)))
# 00000000 ef be ad de be ba fe ca 61 73 64 66 │····│····│asdf│
# 0000000c
11.7 神奇地调用函数
Pwntools的ROP工具的真正威力在于能够调用任意的函数,无论是通过神奇的访问器还是通过ROP.call()例程。
elf = ELF('/bin/sh')
rop = ROP(elf)
rop.call(0xdeadbeef, [0, 1])
print(rop.dump())
# 0x0000: 0xdeadbeef 0xdeadbeef(0, 1, 2, 3)
# 0x0004: b'baaa' <return address>
# 0x0008: 0x0 arg0
# 0x000c: 0x1 arg1
注意这里它使用的是32位ABI,这是不正确的。我们也可以对64位二进制文件进行ROP,但我们需要相应地设置context.arch。我们可以使用context.binary来自动完成这个工作。
context.binary = elf = ELF('/bin/sh')
rop = ROP(elf)
rop.call(0xdeadbeef, [0, 1])
print(rop.dump())
# 0x0000: 0x61aa pop rdi; ret
# 0x0008: 0x0 [arg0] rdi = 0
# 0x0010: 0x5f73 pop rsi; ret
# 0x0018: 0x1 [arg1] rsi = 1
# 0x0020: 0xdeadbeef
11.8 使用函数名来调用函数
如果你的库在其GOT/PLT中有你想调用的函数,或者有二进制的符号,你可以直接调用函数名。
context.binary = elf = ELF('/bin/sh')
rop = ROP(elf)
rop.execve(0xdeadbeef)
print(rop.dump())
# 0x0000: 0x61aa pop rdi; ret
# 0x0008: 0xdeadbeef [arg0] rdi = 3735928559
# 0x0010: 0x5824 execve
11.9 多重ELF
一般来说,在你的进程的地址空间中,一次有一个以上的ELF可用。让我们看一个使用/bin/sh以及其libc的例子。最初,我们看了rop.rcx,这个gadgets是不存在的,因为bash中没有pop rcx; ret这个gadgets。然后,现在我们也有来自libc的所有gadgets了。
context.binary = elf = ELF('/bin/sh')
libc = elf.libc
elf.address = 0xAA000000
libc.address = 0xBB000000
rop.rax
# Gadget(0xaa00eb87, ['pop rax', 'ret'], ['rax'], 0x10)
rop.rbx
# Gadget(0xaa005fd5, ['pop rbx', 'ret'], ['rbx'], 0x10)
rop.rcx
# Gadget(0xbb09f822, ['pop rcx', 'ret'], ['rcx'], 0x10)
rop.rdx
# Gadget(0xbb117960, ['pop rdx', 'add rsp, 0x38', 'ret'], ['rdx'], 0x48)
注意rax和rbx的gadgets是在主二进制文件中(0xAA…),而后两个是在libc(0xBB…)。
现在,让我们做一个更复杂的函数调用吧!
rop.memcpy(0xaaaaaaaa, 0xbbbbbbbb, 0xcccccccc)
print(rop.dump())
# 0x0000: 0xbb11c1e1 pop rdx; pop r12; ret
# 0x0008: 0xcccccccc [arg2] rdx = 3435973836
# 0x0010: b'eaaafaaa' <pad r12>
# 0x0018: 0xaa0061aa pop rdi; ret
# 0x0020: 0xaaaaaaaa [arg0] rdi = 2863311530
# 0x0028: 0xaa005f73 pop rsi; ret
# 0x0030: 0xbbbbbbbb [arg1] rsi = 3149642683
# 0x0038: 0xaa0058a4 memcpy
请注意,Pwntools能够使用pop rdx; pop r12; retgadgets,并说明堆栈上需要的额外值。还要注意的是,每个项目的符号值都在rop.dump()中获取。例如,它显示我们正在设置rdx=3435973836。
11.10 获取一个shell
当我们了解了pwntools的ROP功能时,获得一个shell是很容易的!我们直接调用execve,并从内存中的某个地方找到一个"/bin/sh/x00 "的实例作为第一个参数传递进去。
context.binary = elf = ELF('/bin/sh')
libc = elf.libc
elf.address = 0xAA000000
libc.address = 0xBB000000
rop = ROP([elf, libc])
binsh = next(libc.search(b"/bin/sh\x00"))
rop.execve(binsh, 0, 0)
显示我们的ROP栈
print(rop.dump())
# 0x0000: 0xbb11c1e1 pop rdx; pop r12; ret
# 0x0008: 0x0 [arg2] rdx = 0
# 0x0010: b'eaaafaaa' <pad r12>
# 0x0018: 0xaa0061aa pop rdi; ret
# 0x0020: 0xbb1b75aa [arg0] rdi = 3139138986
# 0x0028: 0xaa005f73 pop rsi; ret
# 0x0030: 0x0 [arg1] rsi = 0
# 0x0038: 0xaa005824 execve
提取ROP的原始字节
print(hexdump(bytes(rop)))
# 00000000 e1 c1 11 bb 00 00 00 00 00 00 00 00 00 00 00 00 │····│····│····│····│
# 00000010 65 61 61 61 66 61 61 61 aa 61 00 aa 00 00 00 00 │eaaa│faaa│·a··│····│
# 00000020 aa 75 1b bb 00 00 00 00 73 5f 00 aa 00 00 00 00 │·u··│····│s_··│····│
# 00000030 00 00 00 00 00 00 00 00 24 58 00 aa 00 00 00 00 │····│····│$X··│····│
# 00000040
十二、日志
Pwntools有一个丰富的内部调试系统,可用于你自己的调试,以及弄清Pwntools幕后发生的事情。
12.1 功能
当你从pwn导入*时,日志功能就导入了。这些功能如下:
-
error -
warn -
info -
debug
例如:
>>> warn('Warning!')
[!] Warning!
>>> info('Info!')
[*] Info!
>>> debug('Debug!')
注意,最后一行默认不显示,因为默认的日志级别是 “info”。
你可以在你的开发脚本中使用这些,而不是打印,这可以让你准确地调控你看到的调试信息量
你可以通过各种方式控制哪些日志信息是可见的,所有这些都将在下面解释。
12.2 命令行
最简单的方法是在运行你的脚本时加入神奇的参数DEBUG,例如:打开最大限度的日志记录功能:
$ python exploit.py DEBUG
这对于查看正在发送/接收的确切字节,以及在pwntools内部发生的事情,以使你的EXP发挥作用是很有用的。
12.3 环境
你也可以通过context.log_level来设置日志的粗略程度,就像你设置目标架构等的方式一样。这与在命令行中控制所有的日志语句的方式相同。
>>> context.log_level = 'debug'
log_console
默认情况下,所有的日志都转到STDOUT。如果你想把它改成一个不同的文件,例如STDERR,你可以通过log_console设置来实现。
>>> context.log_console = sys.stderr
log_file
有时你想让你的日志转到一个特定的文件,例如log.txt,以便以后查看。你可以通过设置context.log_file来添加一个日志文件。
>>> context.log_file = './log.txt'
12.4 管道
每个管子在创建时都可以单独控制其日志的粗略程度。只需将level='...'传递给对象的构造。
>>> io = process('sh', level='debug')
[x] Starting local process '/usr/bin/sh' argv=[b'sh']
[+] Starting local process '/usr/bin/sh' argv=[b'sh'] : pid 34475
>>> io.sendline('echo hello')
[DEBUG] Sent 0xb bytes:
b'echo hello\n'
>>> io.recvline()
[DEBUG] Received 0x6 bytes:
b'hello\n'
b'hello\n'
这适用于所有的管子(process、remote等),也适用于类似管子的东西(如gdb.attach和gdb.debug)以及其他许多例程。
例如,如果你想确切地看到一些shellcode是如何组装的。
>>> asm('nop', log_level='debug')
[DEBUG] cpp -C -nostdinc -undef -P -I/home/user/pwntools/pwnlib/data/includes /dev/stdin
[DEBUG] Assembling
.section .shellcode,"awx"
.global _start
.global __start
_start:
__start:
.intel_syntax noprefix
nop
[DEBUG] /usr/bin/x86_64-linux-gnu-as -32 -o /tmp/user/pwn-asm-0yy12n6i/step2 /tmp/user/pwn-asm-0yy12n6i/step1
[DEBUG] /usr/bin/x86_64-linux-gnu-objcopy -j .shellcode -Obinary /tmp/user/pwn-asm-0yy12n6i/step3 /tmp/user/pwn-asm-0yy12n6i/step4
b'\x90'
12.5 范围
有时你希望所有的日志都被启用,但只针对部分漏洞脚本。你可以手动切换context.log_level,或者你可以使用一个范围内的助手。
io = process(...)
with context.local(log_level='debug'):
# Things inside the 'with' block are logged verbosely
io.recvall()